Strategies to simplify your BDD step definitions
Techniques to boost your efficiency for implementation, writing BDD steps definitions and glue code

If you are a tester, you have probably heard about Behaviour-Driven Development, or BDD in short, and the debates around what it is, and how and what it should be used for. Regardless of what we think about the subject, we cannot deny that test automation tools built to support BDD are with us. They are adopted and used widely in the industry, and they will be with us for some time.
Throughout my testing career, a great portion of my test automation activities involved using some kind of BDD test automation framework. Tools like Cucumber, JBehave and other alternatives. As someone who does coding, I’ve always been interested in refactoring to lessen the amount of boilerplate and duplicate code. This results in improved comprehension and minimising the amount of code. This includes reducing boilerplate code in step definition methods and in glue code overall. Simplifying them. Or getting rid of them entirely if possible.
You may be wondering, “What is glue code?” On one hand, it consists of step definition methods. Ones that tell the BDD automation framework what to execute when it encounters a Given, When or Then step in a Gherkin feature file. Essentially glueing parts of Gherkin plain text files to executable test automation code. On the other hand, it can be hooks. Methods that execute before or after Gherkin Features or Scenarios.
In this article, I’ll present various ways of simplifying glue code and integrating them closer to the language of your automated tests. In the code examples below I’ll use Cucumber and Java code snippets.
Standard Cucumber step definitions
First, to put you into context, let me demonstrate how a regular Cucumber step definition may look like in Java.
Using regular expression as the step pattern:
@When("^user attempts to log in with (.*) username and (.*) password$")
void userAttemptsToLogInWith(String username, String password) { }or using Cucumber expression as the step pattern:
@When("user attempts to log in with {string} username and {string} password")
void userAttemptsToLogInWith(String username, String password) { }The essential parts of this method are:
- one of the
@Given,@When,@Then,@And,@Butannotations placed on the method to signal the type of the step, and make the method be recognised as a step definition, - the step pattern specified in the annotation: this is how Cucumber maps the step in a Gherkin file to this method,
- the method arguments that map to the arguments of the Gherkin step.
Now, let’s look into the ways of simplifications and alternate usages.
Java 8 lambda expression-based step definitions
With the introduction of lambda expressions in Java 8, a lot has improved and become simpler. It has brought forth alternative ways of implementing applications. This includes Cucumber as well as introducing a new way of defining step definitions using lambda expressions.
For that, you have to use a different dependency, namely cucumber-java8. Once you have this configured, you have to make the following changes in your step definition classes.
The class must implement the io.cucumber.java8.En interface (or one of its language specific variants). With this change, new step type specific methods (Given(), When(), etc.) become available in your step definition class.
Your current step definition methods (or at least the ones that you want to simplify) have to be converted and moved to the class constructor. So, the following method:
class LoginStepDefs {
@When("user attempts to log in with {string} username and {string} password")
void userAttemptsToLogInWith(String username, String password) {
//login actions
}
}would become
class LoginStepDefs implements En {
LoginStepDefs() {
When("user attempts to log in with {string} username and {string} password",
(String username, String password) -> {
//login actions
});
}
}From a readability point of view:
- This form eliminates the
voidkeyword and the entire method name, making the definition more concise, and quicker to implement. - However, although the code is more concise, having several step definitions shoved into the constructor can feel overcrowded and sometimes even more noisy than having them in the old-school method form.
There is some debate on whether the regular method form or the lambda one is better. There are both personal preferences and practical arguments (e.g. dependency injection) put on the table, and there has even been some discussion on replacing Cucumber’s Java8 library with an alternative solution.
Patternless step annotations
The following questions can be made for the step annotations:
- Do you actually need to explicitly specify a step pattern?
- Is there an alternative to still have it specified?
Years ago, on a previous project, we had a custom test automation solution and test runner that worked somewhat differently from Cucumber and other BDD frameworks. That solution used its own @Given, @When, etc. annotations with one main difference: you didn’t have to specify the pattern in them. Instead you had to phrase the name of the step definition method in the way it would be used in the Gherkin files.
For example:
@Given
void userAttemptsToLogInWithXUsernameAndYPasswordOnZ(String username, String password, Server server) { }You may have noticed the uppercase letters X, Y and Z. They allowed users to parameterise these methods, and it worked as the following:
- a regular expression was generated from the method name, where X, Y and Z would be replaced with the (
.*) capturing group, like this:
^user attempts to log in with (.*) username and (.*) password on (.*)$- then in a follow-up step, the framework would go through the list of supported parameter type resolvers and perform the following:
- it parsed each argument (the content of each (
.*) group) into the corresponding type specified in the method’s argument list, - then, it injected the resolved values.
- it parsed each argument (the content of each (
This is sort of the opposite way to how Cucumber step definitions work. There, you specify the actual pattern without the method name, while here you specify the method name as a sort of pattern without specifying the actual pattern.
The advantage of this was that you did not have to specify the pattern in the annotation, only in the method name. This resulted in less coding and less noisy code. But, the step annotations still provided an attribute to specify a custom pattern if the default, generated one was not sufficient.
This also made engineers phrase the names of step definition methods in a way they would be used in the Gherkin files, resulting in clearer steps. It also prevented confusion regarding having a step pattern used with a different method name for no proper reason. Like something like the one below would have caused:
@When("user attempts to log in with {string} username and {string} password")
void authenticate(String username, String password) {
//login actions
}Leverage custom IDE integration
Although, using a custom-developed IDE plugin does not necessarily reduce the amount of test code you have, it can at least help increase the level and easiness of code comprehension.
The idea I’ll demonstrate involves a feature called code folding that is a standard one in many IDEs and text editors. Code folding is when an arbitrary range of text in a document becomes hidden (i.e. collapsible and expandable), and is replaced with a custom placeholder text that lets you know a summary of what is under that folded section.
Such a placeholder text may be as simple as an ellipsis (the … symbol). This is used mostly when the content, for example a method body, is not relevant at the moment, and it just needs to be hidden.

Or, it can be actual contextual information that provides the same or almost the same information that the actual unfolded code provides, but in a simpler way. A good example for this is folding anonymous object instantiation in Java to lambda expression style. So, given the following method:
CredentialsProvider getCredentialsFor(String userType) {
return new CredentialsProvider() {
@Override
public Credentials get() {
return credentialsService.get(userType);
}
};
}
the folded code will look like this:

Now that you’ve seen a few simple examples of code folding, let’s see some ideas on how certain parts of step definition methods may be folded to achieve a better comprehension of them.
Use a step pattern in place of the step definition method’s name
In my experience, when it comes to reading and comprehending a step definition method, people focus on understanding it by reading the step pattern instead of the method name. So why not improve this aspect? Since the method name may be a duplicate of the step pattern, and it cannot be omitted if one uses actual methods, let’s try to make it appear in a more concise way.
This involves two steps. First, fold the step pattern in the step annotation into an ellipsis like this:
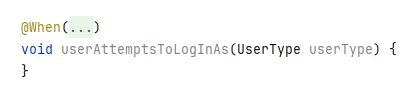
This results in a less noisy code, and you still have the information of what type of step (Given, When or Then) this method is for.
Then, if you prefer reading the step pattern, and the step pattern provides more context for the step than the method’s name, you can go one step further. Fold the method name using as placeholder text the step pattern.

If you have the option, you can fold the public and void keywords as well, so you end up with the following method “signature”:

Of course, if you want to, you can go further, or in a completely different direction, with the customization of this folding. This is up to your personal or project preferences.
Dynamic resolution of steps
Let’s say you have steps that have a clear formalisable format. You don’t want to deal with implementing separate step definitions for each of them because it would be an unnecessary duplication.
One thing you can do in this situation, and what we did on a previous project, is using dynamic parsing and resolution of steps. This eliminated the need to implement actual step definition methods for them. We mostly used it to build validation steps for web UI test automation, like the ones below. (Screaming snake case parts reference Selenium WebElements and Bys.)
Then the TITLE of the RECOMMENDED_BOOKS module should be "Recommended books"Then the TITLE of the first item of the RECOMMENDED_BOOKS module should be "Atomic Habits"Then the second AUTHOR of the first item of the RECOMMENDED_BOOKS module should be “Noone”
As you may see, it kind of works in a backwards order. If you take the last example:
- It locates the Recommended Books module on the page the scenario is currently on.
RECOMMENDED_BOOKShere is mapped to a list ofWebElements. - It gets the
first itemfrom that list, which is the element of an actual book. - It gets the list of
AUTHORs as strings.AUTHORhere is mapped to a By object. - Then, it gets the second item from the list of authors.
- Finally, it compares the found value to the expected one specified in the ‘
should be “Noone”’ part.
All of this was made possible by the implementation of a common parser logic. Once it was put in place, no coding was required to explicitly implement this kind of Gherkin steps. The only coding involved in this area were either bug fixes, improvements to the parser logic or extending the corresponding page objects.
Now, of course one could argue how readable these steps are, or whether they could be replaced with visual testing. But, at that time, it provided a clear structure and format. Customisation of underlying page elements, choosing elements by index, and other goodies too. For us it was a nice way of implementing validation with a minimal amount of coding.
Use frameworks with pre-implemented step libraries
One way of minimising the amount of glue code is getting rid of them entirely. This may be achieved for example by using libraries that provide pre-implemented steps for many common or not so common tasks.
They may also have different templating solutions and expression languages to customise steps and actions with dynamic input data, like various types of request bodies and headers for sending HTTP requests in API tests.
I’m only including brief introductions of some libraries below, just to give you an idea where to begin, then I’ll let you delve into them if you are interested.
Framework |
Summary from the framework’s documentation |
Scenarios are implemented as ... |
| Karate | “Karate is the only open-source tool to combine API test-automation, mocks, performance-testing and even UI automation into a single, unified framework. The syntax is language-neutral … in a simple, readable syntax - carefully designed for HTTP, JSON, GraphQL and XML. And you can mix API and UI test-automation within the same test script.” | Gherkin Features with Karate’s own language parser (instead of Cucumbers) |
| Vividus |
“VIVIDUS is a test automation tool that offers already implemented solution for testing of the most popular application types.”
This includes database, API (Application Programming Interface) and UI (User Interface) testing as well. |
JBehave Stories |
| Citrus YAKS |
“YAKS is a framework to enable Cloud Native BDD testing on Kubernetes! Cloud Native here means that your tests execute as Kubernetes PODs.
As a framework YAKS provides a set of predefined Cucumber steps which help you to connect with different messaging transports (Http REST, JMS, Kafka, Knative eventing) and verify message data with assertions on the header and body content.” |
Cucumber Gherkin Features |
Take scenario development to the code level
Although this approach doesn’t get rid of step definition methods, it simplifies tests from a different, sort of the opposite, perspective of what I introduced in the previous section. Instead of implementing your tests in Gherkin or similar files, and having to bother with step definition implementations, you implement tests as actual code in a Gherkin-like DSL (Domain Specific Language). This way you don’t have to touch any actual Gherkin file. That is what the JGiven framework aims to achieve, or at least how it fits into the topic of this article.
With applying some basic test configuration, and extending some base classes, you can implement “Gherkin” steps and scenarios in regular JUnit, TestNG or Spock test methods. Thus, you also have proper and direct access to the assertion, mocking, etc. libraries that you use, and your test methods would read close to actual Gherkin scenarios with test reports generated accordingly.
The following one is a Given step with a more granular implementation (see the corresponding section in the JGiven documentation):
@Test
public void validate_recipe() {
given().the().ingredients()
.an().egg()
.some().milk()
.and().the().ingredient("flour");
//other steps…
}Or, if you take a more advanced scenario, the JUnit 5 test method below, it executes a parameterised test with multiple different input data. It essentially simulates the execution of a Gherkin Scenario Outline with a set of input data its Examples table would receive.
This example is from the Parameterized Scenarios section of the JGiven documentation, altered for conciseness and to use the more commonly used JUnit 5 parameterised test approach.
@ParameterizedTest
@CsvSource({ "1, 1", "0, 2", "1, 0" })
public void coffee_is_not_served(int coffees, int euros) {
given().a_coffee_machine()
.and().the_coffee_costs_$_euros(2)
.and().there_are_$_coffees_left_in_the_machine(coffees);
when().I_insert_$_one_euro_coins(euros)
.and().I_press_the_coffee_button();
then().I_should_not_be_served_a_coffee();
}This test method would generate the following report, so you would still have proper test reports and living documentation that you can share with various stakeholders.

We can take this example one step further by applying some IDE plugin magic on it. Using custom-developed code to fold in this case, you could bring your test code even closer to how an actual Gherkin scenario would read. Something like this:

Please note that this code folding is not from an existing IDE plugin. It was made specifically for this article for demonstration purposes.
Don’t use BDD frameworks at all
Whether you should implement your tests as BDD scenarios and use a test framework that supports that, depends on the project domain and resources, application type and other aspects.
One argument I have heard many times is the fact that glue code adds an unnecessary layer of abstraction, since it has to be thin, and, in an ideal case, should only delegate test execution to the actual underlying test code.
It is simply worth keeping in mind that you can always opt to implement your tests as regular JUnit or TestNG ones.
A couple of options to choose from
I have described a couple of options that you can utilise in your test suites and during your test automation. They have different learning curves and require different sets of knowledge to apply, so I’m not advocating for any specific solution above. I’m simply hoping I could show you some interesting ways and alternatives to spark your imagination about how you could simplify your or your team’s life when you are using BDD based test automation.
If you think I missed any other ways of simplification, please let me know on The Club (link required).
Resources
- Baeldung - Cucumber with Lambda Expressions
- The Coding Craftsman - Some Cucumber Best Practices by Ashley Frieze
- IntelliJ IDEA documentation - Code Folding in IntelliJ
- DZone - Acceptance Tests in Java With JGiven by Elmar Dott
- OnTestAutomation - To BDD or not to BDD? by Bas Dijkstra
For more information

I develop JetBrains IDE plugins for test automation tools like WireMock, Mockito and others. I'm also a former QA and Test Automation Engineer of more than 10 years.
Comments





