AI doesn’t fail at randomness. It fails at complexity.
09 Jun 2025
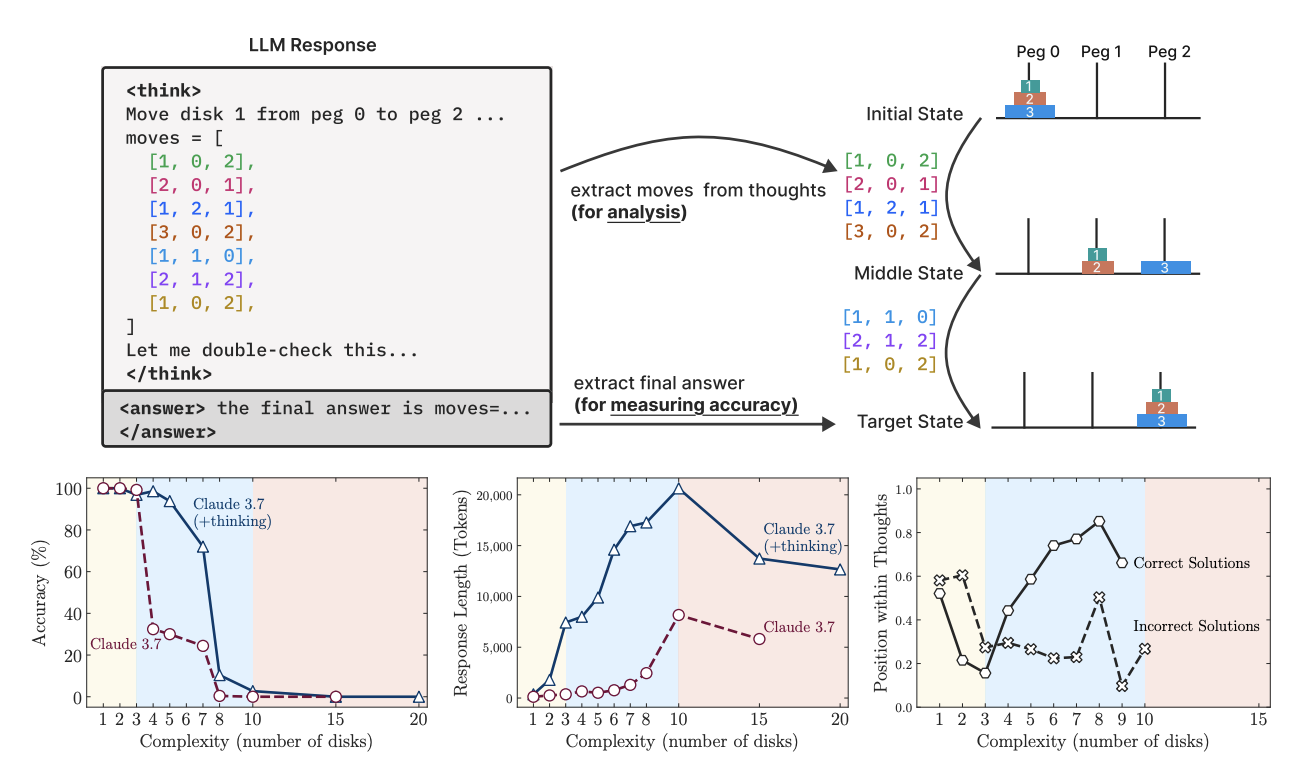
Apple just tested the smartest "reasoning" AI Models out there: Claude 3.7 Sonnet, DeepSeek-R1, OpenAI’s o1/o3.
The verdict?
They didn’t just underperform.
They 𝗰𝗼𝗹𝗹𝗮𝗽𝘀𝗲𝗱 when things got to complex.
Even when you gave them the algorithm, they couldn’t follow it.
Worse, when tasks got harder, they 𝗿𝗲𝗮𝘀𝗼𝗻𝗲𝗱 𝗹𝗲𝘀𝘀, not more.
This confirms what many testers already feel in their gut:
AI looks smart until it has to think.
Because real reasoning isn’t just generating confident answers.
It’s about:
• Navigating uncertainty
• Spotting what’s missing
• Asking, “Wait, does this even make sense?”
And that’s what great testers do every day.
We don’t just validate that something works.
We question 𝘄𝗵𝘆, 𝗵𝗼𝘄, 𝗮𝗻𝗱 𝘄𝗵𝗮𝘁 could break it next.
AI can make us more productive.
But when complexity scales, 𝘁𝗵𝗲 𝗔𝗜 𝗶𝘀 𝗻𝗼𝘁 the reasoning engine.
𝗬𝗼𝘂 𝗮𝗿𝗲.
Original Paper: https://machinelearning.apple.com/research/illusion-of-thinking
The verdict?
They didn’t just underperform.
They 𝗰𝗼𝗹𝗹𝗮𝗽𝘀𝗲𝗱 when things got to complex.
Even when you gave them the algorithm, they couldn’t follow it.
Worse, when tasks got harder, they 𝗿𝗲𝗮𝘀𝗼𝗻𝗲𝗱 𝗹𝗲𝘀𝘀, not more.
This confirms what many testers already feel in their gut:
AI looks smart until it has to think.
Because real reasoning isn’t just generating confident answers.
It’s about:
• Navigating uncertainty
• Spotting what’s missing
• Asking, “Wait, does this even make sense?”
And that’s what great testers do every day.
We don’t just validate that something works.
We question 𝘄𝗵𝘆, 𝗵𝗼𝘄, 𝗮𝗻𝗱 𝘄𝗵𝗮𝘁 could break it next.
AI can make us more productive.
But when complexity scales, 𝘁𝗵𝗲 𝗔𝗜 𝗶𝘀 𝗻𝗼𝘁 the reasoning engine.
𝗬𝗼𝘂 𝗮𝗿𝗲.
Original Paper: https://machinelearning.apple.com/research/illusion-of-thinking

Christine Pinto
Award-Winning QA Leader
Conference speaker on AI and Quality Leadership | Long-time tester | Building tools testers actually enjoy using | Join the quest to level up software quality
Sign in
to comment
Manage your entire QA lifecycle in one place. Sync Jira, automate scripts, and use AI to accelerate your testing.
Explore MoT

Fri, 19 Jun
A half-day educational experience to navigate the world of AI

Boost your career in software testing with the MoT Software Testing Essentials Certificate. Learn essential skills, from basic testing techniques to advanced risk analysis, crafted by industry experts.

Debrief the week in Quality via a community radio show hosted by Simon Tomes and members of the community
