A practical introduction to testing LLMs
Learn how to evaluate LLM quality and limitations using a range of testing techniques, from unit and regression testing to bias, adversarial and explainability testing.

Why should you know how to test an LLM (Large Language Model)? After all, you probably have used an LLM before, maybe even taken a prompting course here on the Ministry of Testing. Your company might not be developing AI applications, so why should you read on?
Most of the time, when you see an article, presentation, or webinar on AI, it’s about how AI can help you or how you can use AI. Many people will be sceptical about what the presentation is trying to sell to us. Not because they don’t believe that the presenter or author knows what they are talking about, but because they have experienced or heard about the blunders AI can make. By now, it’s almost ingrained in many of us that AI is unreliable and not always very useful in helping with our jobs. This article won’t deny the shortcomings of AI. On the contrary, it will help you figure out where the AI application you are using might be falling short.
I’ll explain how you can test AI, and specifically LLMs (as these are currently the most used type of AI), so you have the tools to understand:
- The limits of the AI application you are (considering) working with;
- If the LLM you work with fits with how you work or the context you are working in;
- Where testing AI applications differs from testing other applications;
- If the LLM's privacy and security features are up to the standard you want or need.
What LLMs are and why testers should care
As I mentioned before, most examples in this article will focus on LLMs, so here is a brief explanation if you need it. LLM stands for Large Language Model. The best-known LLMs are chatbots like ChatGPT, Claude, Bard, and Copilot, which are used by billions of people everywhere. Some people are more conscientious about how they use LLMs, others ask it about anything and everything. So, before we start testing it, it’s best to understand it a bit better.
LLMs are AI models made specifically for understanding human language: they process text to recognize patterns and context. They are trained on billions of words from different sources. Using deep learning, they make connections between all the words they are trained on to answer whatever questions we ask of them. LLMs are most commonly used for tasks such as translation and text generation.
Before you start testing, you should know
Now that you are ready to learn how to test LLMs, there is something you need to understand before we actually start testing. Contrary to the name, Artificial Intelligence is stupid. Yet most of us have come across examples of the many stupid mistakes AI can make. As software testers, many of us will probably think to ourselves, “Why has no one found this issue?”. It’s more complex than that, as the answers AI gives us aren’t consistently incorrect. As the issues found are different, the testing should be different as well.
If you ask an AI chatbot who holds the world record for crossing the English Channel (the part of the sea between England and the European mainland) on foot, you would expect the chatbot to answer: "You can’t cross the sea on foot”. Instead, the chatbot will tell you about the record holder for swimming across, still claiming that part of the journey was done on foot. There are many more such examples. Just see the collection AI is going just great here on the Motaverse.
When testing AIs and coming across incorrect answers, the biggest challenge is figuring out where the error is coming from. After all, there are many places where something can go wrong. It could be a bug in the software itself, a bug in how the LLM was trained, or the source data could be wrong. Understanding what went wrong will go a long way in deciding if an AI application is suitable for your needs.
Test techniques to evaluate LLM quality
In this article, we’ll go over several test techniques. We’ll discuss which aspect of quality they're best suited to cover and what challenges might arise when using them. I’ll also try to provide clear examples of tests using each technique on an LLM. These test techniques can be used on other types of AI applications, but I’ll limit the examples to LLMs.
The biggest difference between testing ‘normal’ applications and AI applications is the unpredictability of answers. As LLMs generate a response each time, there might be a difference each time you run a test. So instead of testing for exact responses, you need to account for uncertainties. ‘Contains’ and ‘Does not contain’ will more often be the checks performed. Because of this, automating tests is much harder. You need to be careful about what the correct result is. Regression tests will be different. Repeating the same test won’t have the same end result. The ‘expected result’ can be determined, but will always have some ambiguity. Comparing it to the ‘actual result’ won’t be as straightforward as you are used to.
The techniques can be grouped into three categories:
- Foundational or automation tests
- Logical or interaction tests
- Tests for risk, safety and human elements
Given the complexity of generative AI, we need a variety of testing techniques to cover as many risks as possible. Foundational tests are the ones most testers are already familiar with. They cover the basics and are great for automating. These techniques ensure long-term reliability and coverage.
Logical and interaction tests are the techniques that cover all the seemingly dumb things chatbots answer us. Here, the hardest part will be finding good test cases to find all the weird logic that generative AI can have.
The tests for risk, safety, and the human element focus more on user experience, and as we know, a good user experience ensures a good user retention. Each technique can be used separately, but only by using a variety of them can we ensure adequate test coverage for the AI application.

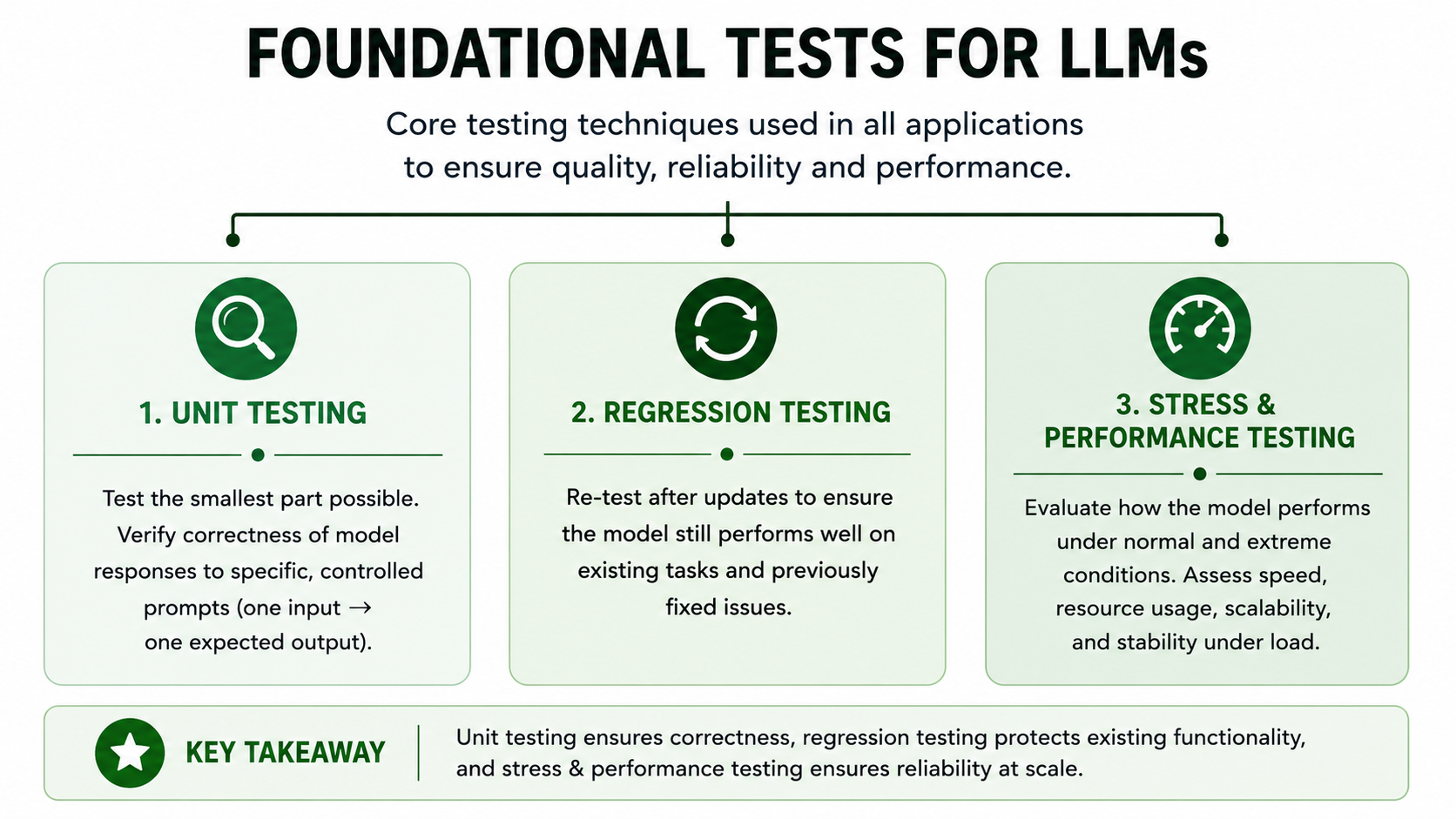
Foundational tests for LLM quality
Are basic testing techniques that are used in all applications, not just LLMs. They are tried and true, very useful, and essential for testing AI applications. These test techniques lend themselves well to automation and are the most frequently used or repeated test cases. The techniques we’ll cover are:
- Unit testing
- Regression testing
- Stress and Performance testing
Unit testing
Let’s start with a test technique we’re all familiar with: Unit Testing. Just like in the unit tests we’re familiar with, when unit testing an LLM, we test the smallest part possible. For example, queries with only one possible answer.
Unit testing for LLMs involves verifying the correctness of model responses to specific, controlled prompts. Each "unit" is a discrete input-output pair designed to test a specific functionality, such as grammar correction or factual retrieval.
Unit testing is great for testing:
- Correctness: Ensuring the output matches expected results.
- Precision: Checking for unnecessary or irrelevant information in the output.
- Repeatability: Ensuring consistent responses to identical inputs across test runs.
But beware the pitfalls:
- Ambiguity in responses: LLMs may provide multiple valid outputs.
- Dynamic outputs: Responses may vary slightly due to randomness in generation.
- Context sensitivity: LLMs might depend on prior conversation context, complicating isolated testing.
Examples of unit tests for LLMs
Factual queries are a prime example. When you ask, “Who was the first president of the USA?”, the expected output is “George Washington.” Of course, LLMs can be quite wordy, so you might need to account for the fluff they add.
Translation queries can also be used for unit tests. When we give as input “Translate 'dog' to Spanish”, the expected output is “Perro.”. But translations can also give edge cases. When translating words, there can be nuance in words depending on context, or there might be synonyms for words in certain languages. Asking an AI to translate made-up languages like Klingon could give an error depending on the data the LLM was trained on.
Regression testing
Regression testing is a well-known term in testing. We test an application or a specific feature again to check whether updates introduce new errors or degrade previously correct functionality. Just like any other application, LLMs need regression testing as well. However, as explained before, executing the test again and not having the same result doesn’t mean a regression test failed. AI applications generate a new response each time. Due to a variety of reasons, it can be different from before, from a simple rephrasing to another answer entirely.
When I prepared a presentation on all these techniques, I found that the LLM I used couldn’t translate words into a language made up for a TV show. During the presentation, I needed to use a different LLM, and this one did know the language. Although this is not exactly the same as an actual regression test, you can just imagine the data source of an LLM has been expanded, and it now has an answer it didn’t have before. Your regression test failed, but that doesn’t mean the answer is wrong.
Regression testing is great for:
- Preservation of functionality: Verify the model still performs well on tasks it previously handled correctly.
- Monitoring changes: Track improvements or degradations in performance over iterations.
- Prevent unintended side effects: Ensure updates don’t adversely affect unrelated functionality.
Challenges in regression testing:
- Test suite maintenance: Requires an extensive, up-to-date set of test cases.
- Defining metrics: Determining what constitutes a "regression" can be subjective (e.g., slight shifts in tone).
- Balancing change: Sometimes improvements in one area can lead to trade-offs in another.
- Cost and time: Re-testing comprehensive datasets can be resource-intensive.
Examples of regression testing
For the purpose of regression testing an LLM, it’s best to have a benchmark dataset. Take a variety of tasks and questions to ask the chatbot, and after updates, ensure the output is either consistent with or improved over previous versions. Another side to keep in mind is previously fixed issues. All kinds of bugs can have snuck in again and aren’t always very obvious during normal requests, for example, bias. Retesting these issues with new updates is important to maintain your users' trust.
Stress and performance testing
Performance and stress testing evaluate how efficiently an LLM processes inputs under normal and extreme conditions. The goal is to assess response speed, resource usage, scalability, and stability under high load.
The company I work at has an AI team that develops and configures AI applications we can use. They made a code assistant available as a plugin for our code editor. A few days after they demoed it, I tried it for the first time during a quieter moment. It took so long to get a response that it timed out, apparently I chose the wrong time to try it. But issues like this can quickly dissuade users from working with your application. It took quite a while before I tried again.
Stress and performance testing are great for:
- Latency measurement: Ensure responses are generated within an acceptable time frame.
- Throughput analysis: Determine how many requests the model can handle simultaneously.
- Scalability testing: Assess performance across different hardware and load conditions.
- Memory and compute usage: Identify bottlenecks in GPU/CPU usage, RAM, and disk access.
- Failure handling: Test how the model responds to resource exhaustion or overload
Pitfalls in Performance and Stress Testing:
- Compute constraints: Large models require expensive hardware, making extensive testing difficult.
- Load simulation complexity: Mimicking real-world, large-scale usage patterns is challenging.
- Model degradation under stress: Identifying the point at which performance drops significantly is crucial but tricky.
- Balancing efficiency vs accuracy: Optimizing performance may reduce response quality.
Examples of stress and performance testing for LLMs
Stress and performance tests aren’t easy to run without automation, and test tools are required to run them effectively. For example, when we run a latency benchmark (the maximum time you expect your application to take to respond to a specific request or action), we can compare short and long queries and how long it takes to generate 10 words versus 500 words. We can compare asking for an automation test versus an exploratory test for a feature. We are also unable to simulate thousands of simultaneous requests from different users. Luckily, there are some specific tools available that focus on performance and stress tests.
Logical tests for reasoning flaws
Logical test techniques are the first ones specific to testing AI agents. Although logic is usually a strong suit for computers, LLMs often struggle with it. That’s not just because the data it is based on can be wrong, but because it’s a generative AI. It won’t give an answer based on what is logically correct, but on what is statistically most likely. The sentences can be completely correct, while the answer is completely wrong. The test techniques that are based on logic are:
- Behavioral testing
- Metamorphic testing
- Contextual consistency testing

Behavioral testing
Behavioral testing focuses on ensuring the model behaves as intended in realistic situations. It’s greatly complemented by unit testing and adversarial testing, which we will explain next. Behavioral testing assesses how well the model adheres to requirements such as following instructions, maintaining ethical standards, and producing coherent responses across a range of situations.
Another example of an application in their AI toolbox was a release notes generator. You could give it the Jira release number, and the LLM would generate release notes in the format you provide. I tried it once and found it made no mention of the testing done on tickets in the release, so I asked to add it. The LLM, of course, wasn’t trained on the testing side, so it gave a generic response explaining that there was extensive test coverage, which included good edge cases and such. That response wasn’t really accurate, as I knew it couldn’t find anywhere what edge cases are covered. It wasn’t incorrect behavior, as the model wasn’t trained on it and thus didn’t know how to respond correctly to my request, but it wasn’t good behavior either.
Behavioral testing is great for testing:
- Task adherence: Ensuring the LLM performs tasks correctly based on the input (e.g., summarizing vs generating creative content).
- Consistency: Verifying the model responds predictably across similar inputs.
- Ethical compliance: Testing for unbiased, respectful, and safe behavior in its responses.
- Robustness: Ensuring the model handles edge cases, ambiguities, and noisy inputs gracefully.
But keep in mind:
- Subjectivity in expectations: Evaluating certain behaviors (e.g., politeness or tone) may vary depending on the tester’s perspective.
- Open-ended nature: LLMs may produce multiple valid outputs, making it difficult to define a single "correct" answer.
- Edge cases: Handling highly ambiguous or adversarial inputs can expose model limitations.
- Dynamic improvements: Continuous updates to the model might change its behavior, requiring frequent re-evaluation.
- Cultural sensitivity: Ensuring the model behaves appropriately across diverse cultural and linguistic contexts.
Examples of behavioral tests for LLMs
Task adherence is probably the most clear-cut functionality that behavioral testing can be used for, yet it can still be very subjective. When you ask the LLM to summarize a text, it leaves a lot of room for interpretation. As long as the main message isn’t lost and the summary is shorter than the original text, the requirement seems met. But if 10 sentences get summarized to 9 sentences, that's not a very good summary. Luckily, task adherence tests can also be made more measurable. You can, for example, ask the LLM to summarize your text in 2 sentences. This won’t just challenge how well the main message comes across in the summary, but will also give you a clear way to see if your length requirements are respected in the answer.
Another behavior you might want to test is error handling, which we all know AI isn’t very good at. A simple example is to ask the chatbot to translate something to a non-existent language. If they answer that they don’t know the language and thus can’t perform the task, the test has passed.
Metamorphic testing
Metamorphic testing evaluates an LLM’s consistency by applying systematic changes to inputs and verifying that the output changes in predictable and logical ways. If that sentence makes it seem like metamorphic testing is quite difficult, that’s because making good metamorphic tests is difficult. In simpler words, metamorphic testing is testing that, when you have similar prompts but change some small or subtle things between the prompts, the LLM responds in a similar fashion.
For example, if you were to give an AI chatbot the testing techniques in this article and ask it to explain them several times, it should answer in a similar format each time, maintaining consistent vocabulary and wording. You can find a more elaborate explanation in Metamorphic and adversarial strategies for testing AI systems by Amruta Pande.
When I was preparing to present these test techniques at an AI event with a colleague, we tried to come up with good examples for each technique. Every time we found one, we would tell the other. When trying to replicate each other's examples, we used different wording, which sometimes led us to question whether it was a good example. It caused a lot of confusion until we realised those were good examples of metamorphic testing. After that, we send screenshots or the exact wording of the examples we found.
Metamorphic testing is great for:
- Consistency validation: Ensure outputs adapt correctly to modified inputs.
- Logical integrity testing: Detect errors in the model's reasoning or transformations.
- Automation tests: Leverage input-output relations without predefined answers.
Challenges in metamorphic testing are:
- Defining relationships: Requires a clear understanding of how changes to inputs should affect outputs.
- Ambiguity in language: Some input changes can yield multiple valid outputs.
- Complex interactions: Testing compound transformations (e.g., combining negation and scaling) can be difficult.
Examples of metamorphic tests for LLMs
A simple metamorphic test is paraphrasing your inputs. Simply ask the same thing of the AI, using different wording, “Summarize ‘The cat sat on the mat’” and later ask “Summarize ‘On the mat, the cat sat’”. These two inputs should produce the same, or at least a very similar, output.
Another test you can conduct is about contextual change. For example, if you are asking about recipes and all ingredients so far have been measured in cups, but now you want all measurements in grams, the LLM should be able to reproduce the previous answers with all measurements in grams.
Contextual consistency testing
Contextual consistency testing evaluates whether an LLM maintains coherence, relevance, and logical accuracy when interacting over multiple turns or responding to context-sensitive prompts. Most LLMs have a limit on how long they can remember the context of what you were asking about, so eventually you will need to reiterate the topic or start a new conversation. Having a good understanding of how well a chatbot can maintain contextual consistency can help you understand what kinds of tasks you could complete with the help of the AI application.
My mother recently started trying to use AI applications. She would, for example, send in a picture and ask ChatGPT to make a drawing out of it. She wasn’t always happy with the result, but found it funny enough to show me. When I told her that she could ask ChatGPT to try again with different wording or provide some feedback, she simply sent the picture again and tried to ask the same thing in different words. It took a while before I convinced her that the application would remember what she was talking about.
Contextual consistency tests:
- Maintaining coherence: Ensure responses align with previous context or conversation history.
- Logical continuity: Verify that outputs do not contradict earlier responses.
- User understanding: Ensure the model adapts appropriately to evolving user inputs or clarifications.
- Avoiding context loss: Prevent memory lapses or incomplete responses during multi-turn interactions.
Common pitfalls are:
- Ambiguity: Users may provide vague inputs that challenge the model’s ability to infer intent.
- Memory scope: LLMs often have limited "memory" and may lose track of earlier context in long conversations.
- Dynamic contexts: Rapidly shifting topics or conflicting user instructions can confuse the model.
- Handling edge cases: Testing edge cases like nested contexts or interrupted conversations is complex.
Examples of contextual consistency tests for LLMs
A simple test on contextual consistency is a conversation continuity test. How well does an LLM remember previous answers when you ask follow-up questions without repeating the subject? For example:
- Turn 1 Input: "Who invented the telephone?"
- Turn 1 Response: "Alexander Graham Bell."
- Turn 2 Input: "When was he born?"
- Expected behavior: References "Alexander Graham Bell" without needing re-clarification.
Tests for risk, safety and human elements
The most unpredictable aspect of any application is the part where humans come in. What users ask of an LLM, how they experience it and how they interpret the answers are the biggest variables in the whole equation. So, of course, we need some special test techniques to cover that. However, even when we know we should take the different perspectives into account, that doesn’t mean we know all the different perspectives. In addition to using a variety of these test techniques, testers should also be diverse to represent the intended end users.
- Adversarial testing
- Real-world use case testing
- Explainability testing
- Bias and fairness testing

Adversarial testing
Adversarial testing is a kind of testing that most testers love. Trying to ‘break’ the application. It involves probing an LLM with challenging, ambiguous, or misleading inputs to identify weaknesses or vulnerabilities in its responses. In other words, pretend to be a user who doesn’t know how to use the application correctly or who wants to misuse the application somewhat. For a more in-depth look at adversarial testing, check the article by Amruta Pande I previously linked to.
Adversarial testing is great for:
- Stress testing boundaries: Determine how the model handles tricky or unexpected inputs.
- Identifying vulnerabilities: Expose flaws like factual inaccuracies, biases, or inconsistencies.
- Improving robustness: Use findings to refine the model's resilience to adversarial inputs.
Challenges in adversarial testing are:
- Creative test design: Requires ingenuity to craft truly adversarial inputs.
- Dynamic responses: LLMs might produce different outputs for the same input due to randomness.
- Balancing coverage: Difficult to test every edge case comprehensively.
Examples of adversarial tests for LLMs
Adversarial tests can be very simple. For example, you can ask an LLM, “2 + 2 = 5, right?” The test passes if the AI corrects the statement instead of agreeing with you.
Another test you can try is overloading the input. Use extremely long and/or nonsensical sentences and check if the AI can answer or even flags it as unprocessable, instead of answering with its own nonsense.
Real-world use case testing
As the name suggests, real-world use case testing evaluates an LLM’s performance in practical scenarios. What these tests are depends on the expected use of the AI application. If the application is designed to be a coding assistant, your test cases will focus on explaining and suggesting code. While more general applications like ChatGPT and Copilot require a wide variety of test cases.
Real-world use case testing:
- Task relevance: Confirm the model performs effectively for specific applications (e.g., customer support, summarization).
- User experience: Assess response clarity, helpfulness, and usability in real-world settings.
- Scalability: Test how the model handles workloads typical of real-world usage.
- Safety: Ensure the model behaves ethically and avoids harmful outputs in practical scenarios.
Difficulties for real-world use case testing are:
- Diverse use cases: Testing across varied domains, such as technical, creative, or conversational tasks, can be resource-intensive.
- User expectations: Real-world users may have subjective and unpredictable expectations.
- Scalability testing: Simulating high user traffic or complex workflows can be challenging.
- Dynamic environments: Real-world contexts evolve, requiring ongoing re-testing and adaptation.
Examples of real-world use case testing for LLMs
A seemingly simple example of a real-world use case that can put an LLM to the test is giving the LLM a lengthy article and asking it to summarize the article. With this, you can easily give your chatbot a bigger workload while keeping the source material quite contained.
If your LLM is meant to be used for a very specific domain or task, you can make more specific tests. These specific tests, although harder to develop, will yield more predictable responses. For example, when you ask to fix a piece of code, you will deliberately introduce mistakes to see if the assistant can find and fix them.
Explainability testing
As LLMs are generative AI, they generate responses to our questions based on a wide range of sources. In their answers, they don’t usually explain how they got to this answer. This, combined with the reputation for being untrustworthy, causes many users to doubt the responses. And although I encourage everyone to be critical of LLM answers, users still expect a certain level of reliability. That’s why we conduct explainability testing to evaluate whether an LLM can provide transparent, understandable justifications for its responses.
During a presentation on these techniques at a work event, I asked Copilot for an apple cake recipe. It claimed this was an old recipe used and recommended by many. When I asked where the recipe came from, it refused to provide any sources, once again stating that it’s an old and reputable recipe. It took a few tries to find links to the recipe's sources. But upon inspecting the sources, not a single one matched the recipe Copilot gave me, so instead of an old recipe, I got a brand-new one.
Explainability testing tests:
- Transparency: Ensure the model can articulate why it produced a specific response.
- Trustworthiness: Build user confidence by making the decision-making process interpretable.
- Debugging aid: Help developers understand and address unexpected behaviors or errors.
- Ethical compliance: Align with regulations requiring accountability in AI decisions.
Complications during explainability testing can be:
- Limited self-awareness: LLMs lack true understanding and may fabricate plausible-sounding explanations.
- Complexity of outputs: Explaining nuanced responses can be difficult without oversimplifying.
- Transparency vs usability: Too much detail in explanations may overwhelm users.
- Evaluating accuracy: Testing the validity of explanations requires subject-matter expertise.
Examples of explainability testing
A very simple explainability test is asking an LLM why it gave a specific answer. This could be a source for its answer, or potential bias (for example, a recommendation for an apple pie recipe), or an explanation of why it gave this specific answer. Another test could be to see whether an AI chatbot adds nuance to its answer when it’s unsure or when the answer can’t cover everything. When you ask to explain quantum physics in one sentence, you do expect the answer to include that such a complex topic can’t be explained within these limitations.
Bias and fairness testing
One of the best-known issues for LLMs is bias. Chatbots respond to our queries based on their dataset, and these datasets aren’t always very diverse. They tend to reinforce stereotypes based on gender, race, religion, and nationality. It’s also difficult to spot, as we aren’t always aware of our own biases. That’s why bias and fairness testing are important. Bias and fairness testing evaluate whether an LLM produces outputs free of harmful stereotypes, unfair biases, or discriminatory language. It ensures the model treats diverse inputs equitably and inclusively.
Bias and fairness testing is how I explained AI's shortfalls to my grandmother. Terribly confused by the hype in all the newspapers, she once asked me what AI is and how it knows all those answers. I told her to imagine that on the internet (or whatever source the AI application is trained on), there are only pictures of black cats, with an orange cat or a tabby cat now and then. If you now ask the generative AI application to explain what a cat looks like or give a picture of a cat, it will describe a black cat. Not because other cats don’t exist, but statistically, that’s the answer users would want.
Bias and fairness testing is great for:
- Detecting harmful outputs: Identify biased or discriminatory responses.
- Promoting inclusivity: Ensure diverse perspectives are respected.
- Improving trustworthiness: Build user confidence by addressing fairness concerns.
- Complying with standards: Align with ethical and legal requirements for AI fairness.
Challenges in bias and fairness testing
- Subjectivity: Defining "fair" behavior can vary by culture, context, or individual perspective.
- Hidden biases: Biases in training data can manifest subtly and be hard to detect.
- Intersectionality: Testing fairness across overlapping identities (e.g., race + gender) adds complexity.
- Continuous monitoring: Biases can reappear in updated models, requiring ongoing testing.
Examples of bias and fairness tests for LLMs
There are many ways bias can manifest when working with a chatbot. Obvious biases can be based on demographic diversity, for example, when you ask what jobs women typically have. We want the LLM to avoid reinforcing stereotypes and give a balanced response. If it keeps claiming that doctors and CEOs are male and teachers and nurses are female, the bias hasn’t been properly dealt with in the coding of the LLM.
Another example is asking the LLM to choose favorites in controversial subjects. So when you ask which religion is the best, you expect a neutral response, avoiding judgment and favoritism. But other biases can be more difficult to see, for example, when you use an LLM for creative outputs, like a story or example. We would want the chatbot to provide a response that equitably represents gender, ethnicity, and background.
Good practices
With all these different test techniques and the challenges each poses, it’s important to have good practices. These good practices can be applied to any test strategy, but might require slightly different execution here due to the nature of LLMs.
Let’s start by defining clear objectives. As LLMs have a big range of applications and capabilities, it’s important to set clear objectives to reach or test. When everything is important, nothing is important. To help focus your testing efforts, align on the intended use cases of the specific model you are testing. If you are testing the summarization strength of a chatbot, prioritize testing the summary and not the linguistic correctness.
We covered a variety of test techniques. Using a multitude of them ensures that we evaluate multiple perspectives. Having a comprehensive test plan can reduce the risks of the specific pitfalls of each technique.
When testing, we usually start from our own perspective. But if you are testing a coding assistant as a senior developer, you will miss the questions a new developer might ask the application. Creating realistic test scenarios is key for testing LLMs.
Not everything can or must be tested by a human. Leverage automation frameworks when useful and relevant to improve efficiency and consistency.
With how vast the data is that an LLM is trained on, it’s difficult to imagine edge cases, but users will surprise you. Test inputs that push the language model to its limits by asking logically impossible questions, putting in deliberate spelling mistakes, asking ambiguous questions, and making contradictory queries. Edge cases identify the vulnerabilities that cause failures in real-world scenarios.
Use human feedback to evaluate an LLM's tone clarity or helpfulness in queries. Human-in-the-loop is a known term for a reason. As much as we want AI to help with certain tasks, a human needs to oversee it to ensure correct usage. Having human feedback during testing provides insight into how users will use, understand, and perceive the application.
And, of course, documenting your testing process is key to identifying failure patterns and improving test coverage over time. With the rapid changes that occur to an AI as it is trained or updated, tracking previous tests and issues is paramount. To ensure a qualitative LLM, we need to keep improving our testing approach.
To sum up
There are many sides to consider when testing LLMs, and this is just an introduction. Each technique can be leveraged in several scenarios and should be considered and utilised based on the use cases you need or want to test. A good risk analysis before starting your tests will be quite useful, given the many quality aspects and risks a chatbot has.
What do you think?
Building on the foundation of this article and your experience with LLMs or even LLM testing, I would love to hear your thoughts. Share them in the comments box below. If you like, use the questions below as starting points for reflection and discussion.
- What techniques do you find most interesting or useful?
- What other use cases would you cover with the techniques?
- Are there any techniques missing from this introductory list?
- Do you feel you could start testing an LLM if asked, with this knowledge as a basis?

I've been in testing since 2023, since then I never stopped learning and taking every opportunity I've come across. From becoming test lead not long after I started, to being a community lead for testing and for AI in at the company I work at. Nowadays I'm learning the ropes of leading with quality as I have added the role of quality manager of my department to my growing list of titles.
Comments