
Rahul Parwal
Test Specialist
Rahul Parwal is a Test Specialist with expertise in testing, automation, and AI in testing. He’s an award-winning tester, and international speaker.
Want to know more, Check out testingtitbits.com
Open To
Write
Teach
Speak
Mentor
CV Reviews
Podcasting
Meet at MoTaCon 2026
Review Conference Proposals
Achievements


















































Certificates

Awarded for:
Achieving 5 or more Community Star badges
Activity

earned:
6.9.0 of MoT Software Quality Engineering Certificate
earned:
Lesson 6 of Advanced prompting for testers
earned:
Lesson 5 of Advanced prompting for testers
earned:
Lesson 4 of Advanced prompting for testers
earned:
6.9.0 of MoT Software Quality Engineering Certificate
Contributions


No matter where you go, MoTaverse is always close to you!


Excited for EuroSTAR 2026 - Anyone joining from MoTaverse?

How do you know if an AI testing tool is worth it?
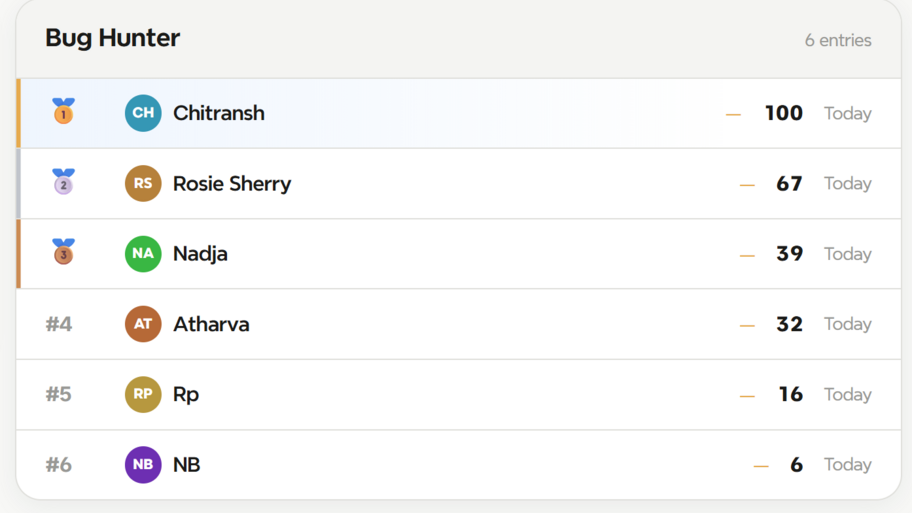
Top three scores from #MoTaversePlay here and claim the top spot: TT Playground - Bug Hunter


I've never done a proper podcast, yet here I am.20 episodes in.Weekly cadence.Great quality conversations.Catching up with old friends.Making some new ones.100% stepping outside of my comfort zone....
AI won't replace testers. It'll replace testers who only run scripts.I understood this years back and so for the last few years, I've been building and growing the opposite path:→ A free Playground...

Rahul Parwal and Rosie Sherry discuss how quality professionals can navigate AI adoption, avoid the noise, and find where human skill still matters most.

This is just a short snippet of ideas from Rahul's recent Masterclass on A tester’s guide to AI guardrails
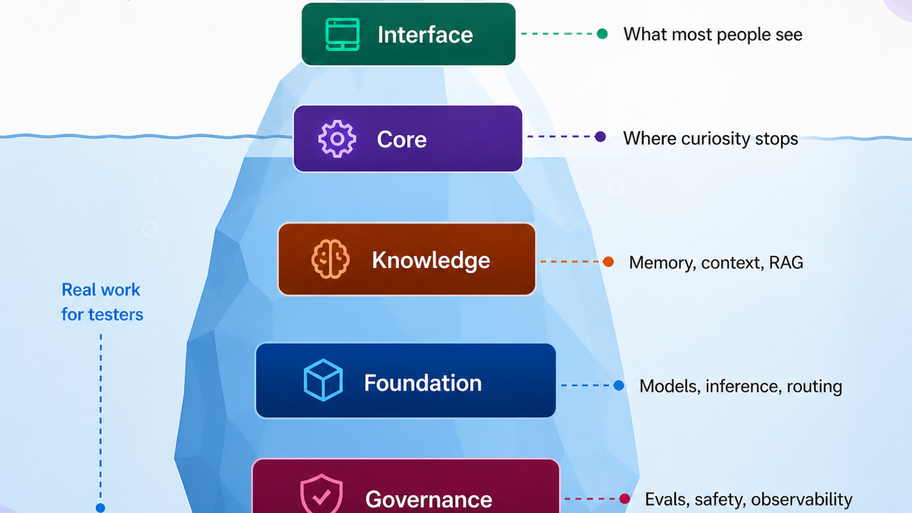
AI agents are becoming the new OS for building, testing, and shipping software.Don't stop at the interface level. Go deep, there is a lot out there.Good read for MoT #Pro members: A guide to...
