Creating self-healing automated tests with AI and Playwright
Reduce test automation maintenance with AI-powered self-healing tests in Playwright

"As soon as automated scripts are written, they need to be maintained on a regular basis, leading to more work that takes time away from other needed testing or development for the project. This is where AI comes in. Integrating AI language models with Playwright can create a powerful self-healing automation framework."
Introduction
Test automation is vital to efficient software testing under ever-changing conditions. Writing test automation for continuous development is priority at most companies that have teams dedicated to software quality.
People ask me frequently how to reduce the time and cost of test automation maintenance. Wouldn't it be great to get rid of maintenance completely… or at least reduce it as much as you can?
Can you do that? Yes, you can! This article is about how to combine Playwright, an open-source test automation library, with AI language models (LMs) such as Groq, Llama, and Mistral, to:
- Assist you in building test automation by making code suggestions and analyzing your code
- Create a suite of tests that "fix themselves" with the assistance of language models so that you do not have to intervene manually each time code changes and an associated test fails. This is what is known as "self-healing."
What can AI do to optimize test automation?

Source: https://medium.com/@john.gluck/the-cost-of-automated-testing-69e0730d891e
Test automation is now standard in the software testing field. One of the goals of good test automation is to reduce the need for human intervention and maintenance.
In practice, this is far from the case. As soon as automated scripts are written, they need to be maintained on a regular basis, leading to more work that takes time away from other needed testing or development for the project.
This is where AI comes in. Integrating AI language models with Playwright can create a powerful self-healing automation framework. A solid integration enables the LMs to use the many capabilities of test automation tools like Playwright not only to verify code but also to interact with the browser's current state. These strategies provide a rich context to LMs, resulting in increasingly accurate suggestions over time.
Benefits of integration:
- Enhanced code verification: Language models can analyze code within the context of browser interactions, leading to more accurate verification and eliminating hallucination. (I discuss hallucination as a common problem later in this article.)
- Self-healing tests: LMs can react to the current application state passed to them by automation frameworks and, if needed, fix tests on the fly, without human interference. With self-healing enabled, the automated tests will not fail simply due to a new element identifier, for example. And this greatly reduces downtime and maintenance efforts.
Working with LMs: maximizing advantages and handling common problems
Language models present major advantages for those who are trying to solve their test automation maintenance problems.
To the test automation engineer, LMs offer:
- Code analysis: Understanding and interpreting code snippets
- Suggestion generation: Providing code completion and optimization suggestions
- Error detection: Identifying potential issues and suggesting fixes
And ultimately you can combine those powerful features into a self-healing solution for test automation.
To develop a solid solution, however, you'll need to address some common problems that LMs present.
Outdated information
The problem
You may make every effort to train your LM using the most current data in your repositories. However, this data will eventually grow stale. For example, your test automation may require the latest version of Java, but your LM knows only about an older version.
Possible solutions
Regular retraining of LMs
- Scheduled updates: Retrain the LMs on new training data on a scheduled basis. If a trained model is unable to predict the probability of the next words correctly, the quality can improve over time with regular retraining. Retraining the model is the most obvious way to ensure better responses. With retraining, you can ensure that your LM is up to date with new languages, new APIs, new libraries, and so forth.
- Incremental learning: Update the model incrementally with new data instead of retraining the model from scratch. Incremental learning can be more efficient and allow the model to learn something new gradually.
Integration with Live Data Sources
- APIs and data: If we connect the LM to an API and a live data repository, we can provide more meaningful information to the LM in real time. For example, pairing with GitHub or wider code repositories can give access to the most up-to-date snippets and documentation.
- Real-time feedback: A feedback process with crowdsourcing allows users to submit reports of outdated or inaccurate suggestions. This information could be used to update the knowledge base of the model in real time.
Hybrid Approaches
- Static and dynamic data: Combining static training data with dynamic real‑time information is a hybrid approach reminiscent of that of a human expert whose personal copy of a book may be out of date, but they obtain up-to-date information from live demonstrations.
- On-demand updates: You can configure the model to request updates when it is confronted with situations it hasn’t encountered before.
How we addressed the outdated information problem
See the deep dive section below.
Hallucinations
The problem
When the output of a language model is wrong or nonsensical, this is known as a hallucination. It happens when the model predicts an input that’s not valid and meaningful in the input context.
Possible solutions
To deal with hallucinations, we can create high-quality data, use context-aware prompt engineering, and do domain-specific fine-tuning. And we can establish a verification service that can call back the LM to fix the problems.
How we addressed the hallucination problem
See the deep dive section below.
Slow response times
The problem
This is the length of time the LM spends processing a query and generating a response. Long response times can become taxing, limiting the utility and ease of assimilating LMs into high-tempo workflows.
Models are resource-intensive, but self-healing automation requires fast replies.
Possible solutions
Optimizing model performance
- Model pruning and quantization: reducing the size of the model through pruning (removing infrequently used or optional parameters) can increase response rates significantly without a significant hit to accuracy.
- Efficient architectures: Models with efficient model architectures, such as those that are optimized for fast inference times, are ideal.
Enhancing hardware and infrastructure
- High-performance computing: For model inference, high-performance GPUs or specialized hardware such as TPUs (tensor processing units) can help to speed things up.
- Distributed systems: Distributing model inference across several servers can lead to more responsive systems by minimizing latency.
How we addressed the issue of slow response times
Our solution did not require a large language model. So we chose the speed-focused models offered by Mistral, Llama, and Groq. Groq in particular features an LPU inference engine, reducing the energy costs of our solution.
This graph represents a comparison of response times and response quality generated by several language models on the market now.
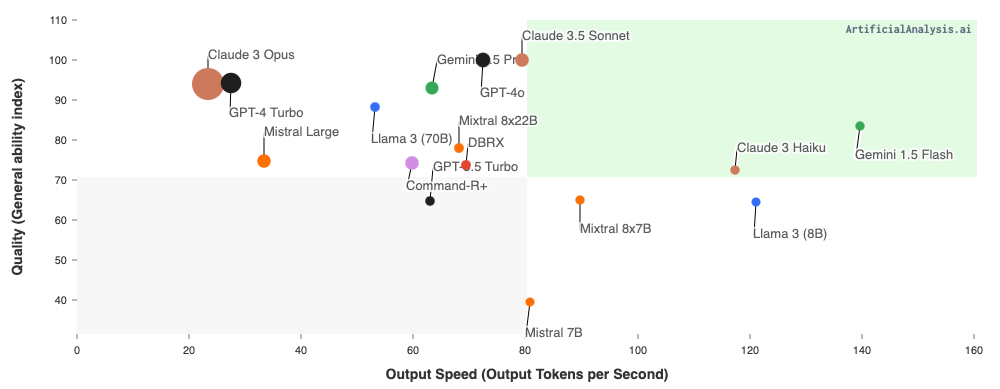
Source: https://artificialanalysis.ai/models
Please also see the deep dive section below.
Poor response quality due to context constraints
The problem
"Context length" refers to the amount of text or code the model can consider at once. And an adequate context size, or the "context window," is critical when it comes to generating correct responses. We need to be able to provide enough context so that the model can make the best possible decision.
Limited context length can result in less accurate or incomplete suggestions, since
the model might not have access to all the necessary information to make an informed
decision.
Possible solutions
Context management strategies
Context window extension: Extending the context window of the model can allow it to process and consider more information at once. Advanced models and techniques are being developed to handle longer context lengths more effectively.
Context chunking: Breaking down large contexts into smaller, manageable chunks that can be processed sequentially or in parallel can help the model retain relevant information over longer sequences. However, this would mean running into rate-limiting issues. Context window growth has been exponential until now, and the models need to manage the quality along with the context window length.
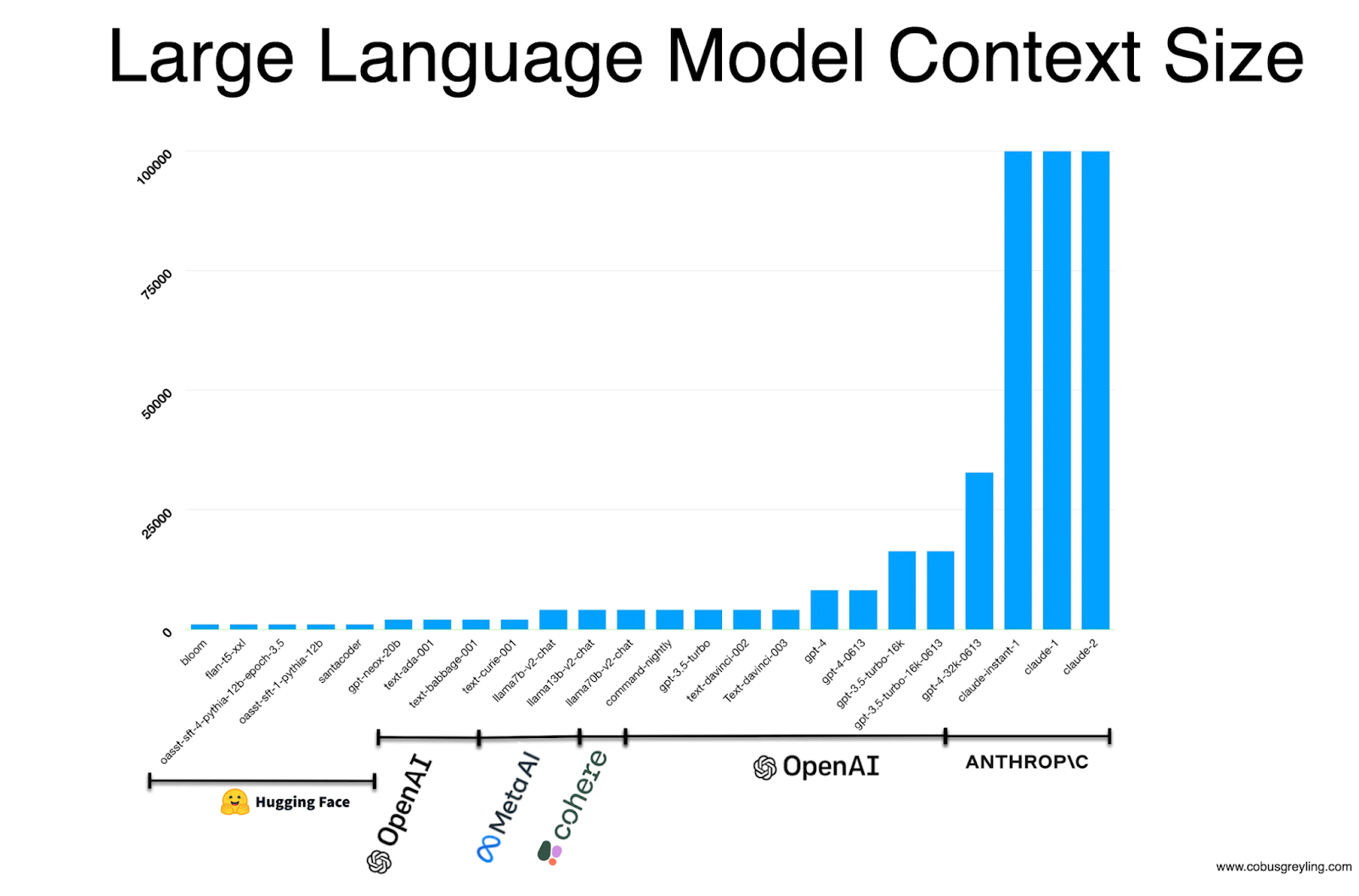
Source: www.cobusgreyling.com
This means that to increase the context window in a well-managed way we need to get better hardware capabilities.
How we addressed it
See the deep dive section below.
Which types of maintenance does our solution do on its own?
- The first level of checks for failing tests is done by the language model, and fixes are done by the language model too.
- Changes in test cases are automatically adapted to the test scripts.
What still requires human intervention?
- If the failure is actually a bug in the application under test, the LM will not be able to fix the test script and testers need to log bugs for the issues.
- Human testers still need to make sure that updates to requirements and design are reflected in the test cases.
- If the LM is not able to fix the failing test case after three tries, testers need to look at the test case and fix it themselves. (The verification system increases the success rate of code fixes, which is now at 90 percent.)
A quick walk through our solution's decision flow

- Our test cases live in Jira, and we use Zephyr Scale as a test management tool. If there are any new test cases or changes to existing ones, our solution pulls them into its local storage of test cases.
- Playwright then coordinates with Llama to generate the needed Javascript. The Playwright test runner verifies the generated code.
- If the test runner throws an error, the model adjusts the code and the test is re-run up to three times.
- After the generated code passes, the code is then sent to Mistral to convert it to Playwright script. The new code is added to the test script file.
- Assuming that the test case is up to date: if a test case fails during a test run or verification process, Llama is called to verify the code and understand the problem. Llama then fixes the code and sends the test to the test runner for a new run. If the updated test does not pass after three tries, the process stops.
- If Llama is unable to fix the code after three test runs, an actual bug in the product code may be the problem. To save effort, Llama stops the flow and throws an error for a failed test case so that the user can look into it. All these failures and passes are reported via Playwright as if it were a standard test run.
- Once the code is fixed, the new test script replaces the old script.
Demonstration time!
Please watch this video describing our implementation, complete with narration. If you need captions, you can enable them in YouTube. I describe the solution in more detail below.
What does the demonstration video tell us about our solution?
One of the most impressive aspects of the demonstration was the seamless interaction between the language models and Playwright. Each tool leverages the capabilities of the other to achieve optimal results.
LMs can fix code if there are invalid responses
The language models analyze the test script, identify invalid responses, and generate correct code to fix the issues. This dynamic interaction highlights the potential for real-time code verification and correction, reducing the need for manual intervention.
In the screenshot below, you can see that the LM made an attempt to generate a fix but it was still incorrect on a new Playwright run. On the second attempt to fix the code, the test ran successfully and the code was accepted.
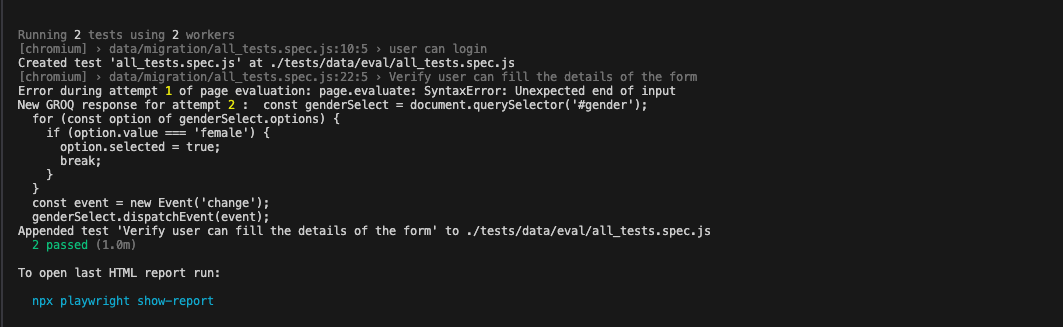
Context window allows only one test case to be run at a time
Another important observation was the limitation posed by contextual issues. The language models struggled to handle more than two test cases simultaneously due to their context length limitations and rate limits.
Because of this, we are dealing with test cases one by one and not in parallel. This could be improved by getting more hardware for models with bigger context windows. But for now, the implementation remains compliant with model rate limits.
Response time is limited by hardware
The demonstration also gave an insight into the impact of hardware limitations on the performance of the integrated system. It took approximately one minute for the tools to identify and generate correct code for the issues. This response time, while acceptable, could be significantly improved with better hardware
How we handled common AI challenges
Earlier in this article, I described some common AI challenges and some possible solutions to them. Here's how we handled them.
Replacing outdated information
One of the challenges we faced was to get the dynamic components loaded at runtime. We could get the DOM structure from the code in the background, but in that case, the dynamic components loaded at runtime would be missing, which would lead the LM to respond to outdated information.
Test automation tools have information about the current structure of the DOM, which is the most up-to-date state of the data. So we used Playwright's ability to extract the current DOM structure to feed it to the LM along with every request.
const PageDOMBody = await pageDOM('body').html();
Eliminating hallucination effects
To fight the problem of hallucination we introduced a verification system that harnesses Playwright's ability to run the generated Javascript code independently. We also used all of the models' code analysis, suggestion generation, and error detection capabilities.
We set the maximum number of fix attempts to three. Usually the model catches the hallucinations within three tries. If the problem persists, there's probably a bug in the product code or something about which the model did not have enough information.
async function evaluateGroqCall(userInput,PageDOMBody,page){
// Create the message section with the parts and additional message
const messages = createGroqMessages(userInput, PageDOMBody,200000);
let groqResponse = await groqCall( messages,PageDOMBody);
let result;
const maxAttempts = 3;
let attempts = 0;
while (attempts < maxAttempts) {
try {
result = await page.evaluate(groqResponse);
// If evaluation is successful and no issues detected, break the loop
break;
} catch (e) {
const errorMessage = e.message.split('\n')[0];
if(errorMessage.includes("Verification failure"))
{throw new Error(errorMessage)}
console.log("Error during attempt", attempts + 1, "for generating code:", errorMessage);
attempts++;
if (attempts < maxAttempts) {
messages.push({
role: "user",
content: `on running it the issue was this: ${errorMessage}. Refer again to the DOM and the error message and think of another way of doing the task`
});
groqResponse = await groqCall(messages, userInput);
console.log("New generated response for attempt", attempts + 1, ": ", groqResponse);
} else {
// If maximum attempts reached, throw the final error
throw new Error(`Failed after ${maxAttempts} attempts with error: ${errorMessage}`);
}
}
}
return groqResponse;
}
Optimizing response time
When we look at models like OpenAI, the response time is usually in the range of two to three seconds. But, we needed a faster solution. We chose Mistral and Llama with GROQ, giving us a typical response time of milliseconds.
Setting the right amount of context
The context window for models like openAI is roughly 28k tokens, but since our context was reaching 30k, we needed a model that could accommodate that.
To handle this issue we calculated our average DOM size which was roughly 20k-30k tokens on the higher end. This made us lean towards Llama's llama-3.1-8b-instant model which can tackle 150k tokens a minute, guaranteeing safe executions.
In simple words, we have implemented a context window extension by choosing a model that takes a larger context but is just big enough for our implementation needs: Llama's llama-3.1-8b-instant model.
How you can adapt our solution to your environment
Test automation framework
Playwright has a page.evaluate() function that runs the code generated by the LMs. You can use any tool you want to achieve the same results.
Playwright:
result = await page.evaluate(groqResponse);
In Selenium, using execute_script.
result=driver.execute_script(script,*args)
In Cypress:
cy.window().then((win) => {
win.eval('console.log("Hello from Cypress!")');
});
We are not restricted to any one automation tool; we simply use it as a runner for the purposes of testing code generated by the LMs.
Language models and hosting
The current implementation uses Llama and Mistral. Llama generates Playwright scripts and Mistral generates Javascript code that is injected into the script execution functionalities of Playwright. Both models were hosted in GROQ, which offers high performance and quick results!
Please feel free to choose any model you like. https://console.groq.com/docs/quickstart. You can even host your own LM’s if you wish.
What's in store for our solution in the future?
For future iterations, we are exploring other models that might be able to handle bigger contexts and provide a faster response time.
Also, as the context window grows, we can create test cases with LMs that know about our entire solution, so that the whole flow can be automated.
For more information
- Don’t Be a Fool With a Tool ‒ Fundamental Knowledge for Proper Test Automation, Christian Baumann
- Automating Mobile Testing and Drastically Reducing Maintenance with AI, Sam Ostrom
- Ask Me Anything - Playwright, Butch Mayhew

Shray is a seasoned professional with over a decade of experience in banking, banking risk, marketing, stock market trading, FPGA and actively helping companies adopt AI for the quality of their product and significantly reducing their costs. He has led teams and created test architectures from scratch, focusing on establishing test automation frameworks and completing CI/CD workflows according to the company budget and technical requirements. His tool kit includes Selenium Web Driver, Cypress, Playwright, and RCPTT.
Comments




