Moving fast and breaking things? Build reliable software from day one instead
Focus on smart testing, risk reduction, and team habits that prevent firefighting to build reliable software from the start.

Picture this: It is Thursday afternoon. Your team just deployed a major feature update. By Friday morning, your email is buzzing with bug reports. The weekend arrives, but instead of disconnecting, you are fielding customer complaints and emergency hotfixes. Monday's sprint planning becomes Tuesday's damage control session. Sound familiar?
We’ve normalized this cycle: the sprint ends, features are deployed, bugs surface, and the next sprint turns into damage control. We call it "moving fast and breaking things." But if your team is always fixing what was just built, is your team really moving fast?
Progress is more than just deploying features to production
If your team measures "progress" by how swiftly code is deployed to production, you are likely to go off track. Deploying code isn’t the goal. Anyone can test. Anyone can release features. The real challenge is releasing something reliable: something that works, something that can evolve, and something that a user can rely on.
Progress isn’t measured by how many features a product team has launched. It’s how far forward you helped the product actually move. If you move forward ten steps but then have to go back eight to fix problems, you’ve only really made two steps of progress, even if it felt like a lot of work.
Traditional velocity metrics include story points completed, features rolled out, commits pushed, number of tests run . But those metrics are misleading. They may look impressive on a dashboard, but they do not tell the complete story. What about rollbacks, regressions, and hotfixes?
A team that spends weeks patching what they just deployed isn’t fast. They’re just noisy. Here is what I often say to my team: “Fast progress does not matter when we are constantly stuck resolving bugs and broken user flows.”
The goal is not perfection. It is about building sustainable forward momentum (real velocity).
What actually slows down a software development team?
Bugs discovered late in development or in production are not just minor hiccups. They derail timelines, redirecting the efforts of developers and testers from creating a product to root-causing and fixing problems. Product leads move from planning to damage control. Support teams receive, handle, and respond to complaints. Every release turns into a gamble instead of a confident step forward, shattering trust in the testing team. Production bugs are especially painful since they are harder to trace, harder to fix, and far more visible when they fail. Trust, both internal and external, erodes.
What could have been resolved in 15 minutes during development now takes three people, two hours, a lot of testing and an endless email thread.
What does meaningful speed in code delivery look like?
Real speed is not about skipping steps, it's about removing friction from your entire product development process. The fastest teams are often the ones that spend more time on seemingly "unproductive" activities like code review, testing, and documentation. What's more, they do these activities as a team, not as isolated people in narrowly defined roles.
Here is what a "fast" team looks like:
- Confidence in your releases: The team launches products and features without anxiety. They have built systems to capture issues. These systems catch issues before customers do.
- Fearless refactoring: Instead of being trapped by technical debt, they spend a bit more time early in the development cycle improving overall architecture, knowing they’ll catch regressions early.
- Predictable delivery rhythms: Fast teams deploy regularly and reliably, not reactively. Customers know when to expect new features. Stakeholders can plan around reliable delivery schedules.
- Reduced interruption overhead: When you are not constantly firefighting, your team can maintain focus on important work. Deep work becomes possible again. Strategic thinking does not get pushed aside by urgent bug fixes. Innovation happens during work hours instead of late-night heroics. To learn more, have a look at The Efficiency Trap - Building Fast vs Building Right.
- Smooth feature validation: When features move through your testing and review process efficiently, without multiple rounds of "wait, this breaks when..." discoveries, you know you have found your rhythm. The goal is not eliminating feedback, it's eliminating surprises.
I always say this in my team meetings:
"I am not asking for zero bugs in our releases. I am asking: will this change break something we already fixed?"
How do you deploy code to production without breaking something?
You're a lot less likely to break something on deployment if you add just enough structure to make testing a useful activity, not a ceremony of useless processes.
Define "done" as "no repeat bugs"
Include a confidence check in every user story. Ask: Where could this break something else? Which flows might this change affect beyond its primary function?
This is not about being pessimistic, it is about realistic risk assessment.
Spend more time testing the 20 per cent of features that could break everything
Test critical flows harder. These include payment flows, onboarding sequences, and core functions your product depends on. Use the 80/20 rule for your validation efforts. Focus on what matters most.
You do not need to test everything equally. Use lightweight automation or simple checklists for areas that could cause the most damage if they fail.
Encourage small, safe steps
Smaller changes mean fewer surprises. Do not let “we will test this later” become “we will fix this in production.” Set aside 15 to 30 minutes daily for quick validation checks to reduce or eliminate weekend hotfixes.
As testers often say, “Testing isn’t extra work. If we test well, we don't have to repeat the same work five different times.”
Shift the culture, not the timeline
Common objections:
- “We do not have time for more testing.” But you are already spending time fixing the results of inadequate testing.
- “Our codebase is too complex for thorough testing.” That’s why you need better testing.
- “Testing slows us down.” Bad testing does slow you down. Good testing prevents delays.
This is where product leaders can make the biggest difference by actively shaping how developers, testers, and stakeholders interact throughout the development process.
Celebrate the right behaviors. In addition to celebrating features released, start celebrating:
- Bugs caught early
- Devs who ask great questions
- Testers who identify issues that would have been expensive to fix later
Change the timing of conversations about testing.
- Involve testers early in design conversations
- Make risk reduction part of your initial estimates, not something squeezed in later.
- Weigh the effort to build and the effort to make sure it won’t break anything else.
Want to strengthen that shift-left mindset? Read “How Testers Can Help Build Scalable Products: A Shift-Left Approach.” It’s a tactical guide to add value from day one, not just at release.
Estimate beyond coding: account for validation and integration. Testers frequently estimate the time to test code, but they don't account for the time to validate that the code works correctly, integrates properly, and won't break existing functionality. This leads to systematic underestimates that put pressure on validation activities.
Start including de-risking activities in your estimates: time for code review, time for integration testing, time for edge case validation, and buffer time for addressing issues that surface during validation.
If you're always fixing defects, when are you building the product?
Products grow by solving user problems consistently, not by fixing bugs.
If 30 percent of your capacity goes to fixing issues in previously completed work, that’s not just 30 percent slower. That’s 30 percent backward. The cost isn’t just time. It’s just lost focus, missed opportunities and deferred strategy.
Fixing the results of oversights all the time fractures your ability to think long-term.
Imagine a three-month period where nothing you deployed needed rework. What could your team have built?
Reliability creates trust that compounds over time
Customer’s POV: Reliable products build customer trust. If your customers trust you, they tolerate minor issues better, they recommend your product to others, and provide useful feedback when encountering problems.
Company’s POV: When internal stakeholders trust your team's delivery, they give you more autonomy, better resources, and more interesting challenges to solve.
More trust, better projects, more success leads to even more trust.
In contrast, teams that frequently deploy broken features get:
- More scrutiny
- Frequent check-ins, and more conservative timelines
- Slower momentum
Define before you build. Clarity creates speed
Chaos often comes from lack of clarity, not from complexity.
When teams rush through planning, skip design documentation, make assumptions instead of asking questions, and start coding before understanding requirements fully, they create chaos that seems to come from external pressure but is actually self-inflicted.
Ask more questions earlier:
- What problem are we solving?
- What could go wrong?
- How does this fit with our architecture?
Clarity isn’t slow. Confusion is.
Don’t just build: maintain what you’ve already deployed
Healthy product teams maintain a sustainable balance between building new capabilities and maintaining existing ones. This is not a static ratio. It changes based on your product maturity, technical debt levels, and growth stage. But those changes should be intentional, not accidental.
Balance depends on maturity:
- Early stage: 80 percent building / 20 percent maintenance
- Mature products: 60 percent building / 40 percent maintenance or 50/50
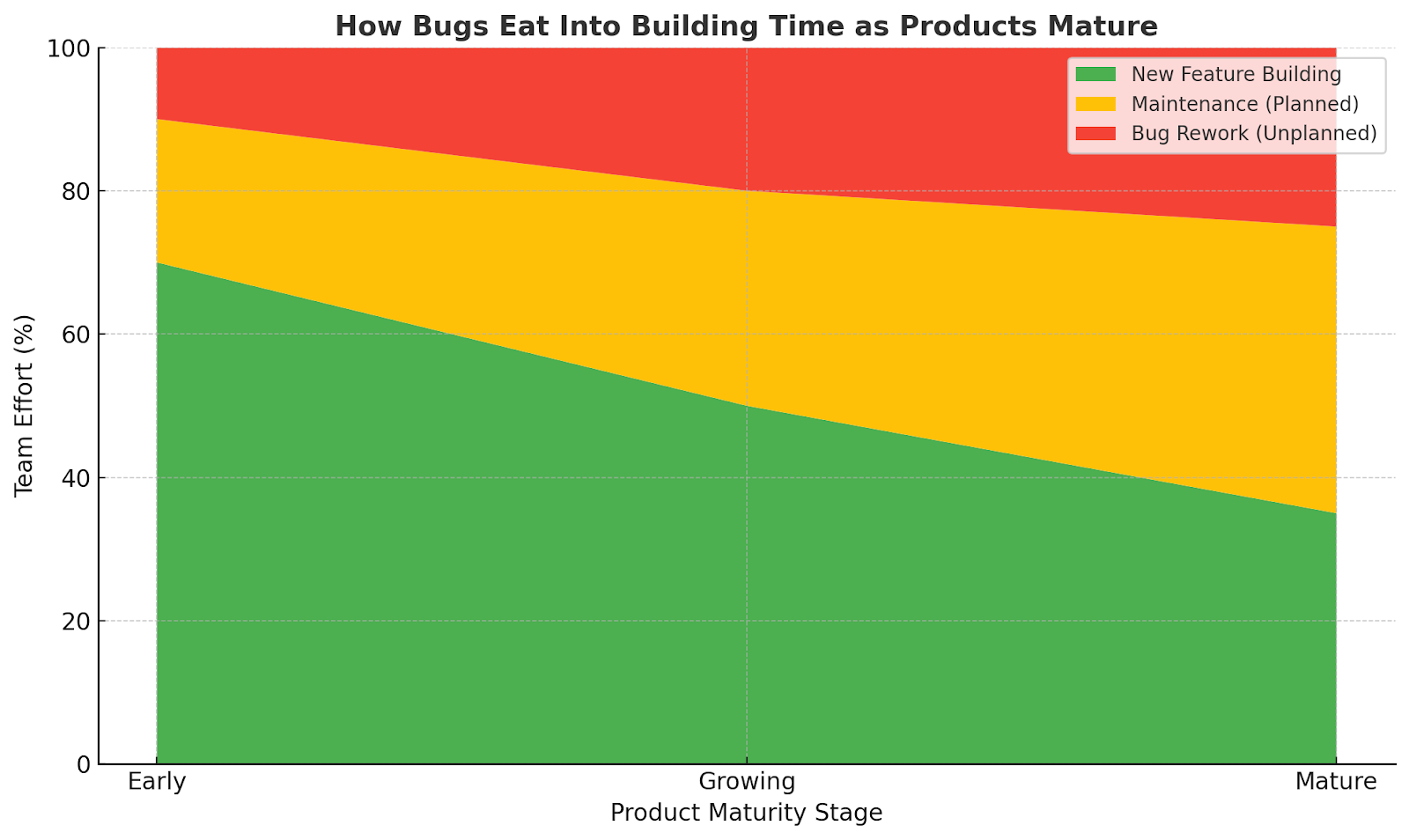
But if you’re spending more than half your time fixing past work, you're stuck. You're not building. You're circling.
Ready to change your development and testing approach?
You can’t transform your entire process overnight. Start small. Focus on high-risk flows.
Start with your biggest pain points
Identify your top two or three "it always breaks here" user flows and prioritize de-risking them first. These are usually easy to spot: they are the features that generate the most support tickets, the workflows that cause the most user frustration, the code areas that your developers dread modifying.
For each of these problematic areas, ask: what specifically keeps going wrong? Are there edge cases we don't anticipate? Integration issues between systems? Performance problems under load? User interface confusion? Data validation failures?
Once you understand the pattern, you can address the root cause rather than just fixing symptoms repeatedly.
Change your planning questions
Add one simple question when you begin: "What would confidence in the reliability of a feature before releasing it look like here?"
Confidence could mean testing the feature with realistic data volumes. Or checking how the feature behaves on mobile devices. Or even validating that the feature works correctly for users with different permission levels.
Shift from "Is the code done?" to "Is the problem solved reliably?"
Track metrics that measure real progress, not just team activity
Start tracking metrics that reflect real progress rather than just team activity:
Time to recovery: When issues do surface, how quickly can you identify, fix, and deploy solutions? Faster recovery times reduce the impact of problems and maintain user confidence.
Regression rate: What percentage of your releases introduce problems in previously working functionality? This metric directly measures the quality of your development process.
Support ticket trends: Are support requests increasing or decreasing over time? Are users reporting more bugs or asking more questions about how to use features successfully?
Planned versus reactive work: How much time does your team spend on planned, strategic work versus reactive firefighting? Teams that spend more time on planned work generally build better products over time.
Bugs are technical debt
Every bug is time borrowed. Sometimes that’s strategic. Usually, it’s “accidental,” known as testing oversights.
Treat bugs like tech debt: they are conscious trade-offs that come with repayment plans. Prevention is almost always cheaper.
Every bug represents a choice to deploy now and pay later. Sometimes that is the right choice for early-stage products or time-sensitive features. Making it a conscious choice with awareness of the real costs helps you take care of the quality before deploying.
The long game: test to build things that last
Reliability is a compounding advantage. It unlocks trust, speed, and better work.
"Move fast and break things" got us here.
"Move a little slower and build things that last instead" will get us out.
The choice is yours. You can keep "moving fast and breaking things," accepting the hidden costs and accumulated frustration that come with that approach. Or you can start moving a little slower and building things that last, creating positive momentum that compounds over months and years.
The time you spend preventing bugs isn't a delay. It’s the investment that makes real speed possible.
What do you think?
Have experiences or thoughts about balancing speed and reliability in software delivery? Share them in the comments below. Use the questions below to help you reflect and discuss.
Questions to discuss:
- Does your team celebrate deploying features or catching issues early?
- How much time do you spend firefighting compared to building new capabilities?
- What small changes have helped you deploy with more confidence?
For more information
- Do Not Build Features, Solve Problems: A Customer-Centric Approach, Ishalli Garg - Medium
- How does development cause bottlenecks? - Club forum topic
- When Testers Deal With Process Debt: Ideas to Manage It And Get Back To Testing Faster, Melissa Eaden - MoT article
- Fixing a bug vs fixing a feature, Hanisha Arora - Blog

I enjoy exploring how people solve problems, how quality shows up in everyday habits, and how teams build better experiences for users.
Comments






