One team, one goal: The reality of introducing a unified testing strategy
Find out how a large, cross-functional tech team unified testing to improve quality at scale

How explosive growth in size and complexity led to testing chaos
We work at Autotrader, a digital automotive marketplace with over 1,000 employees, and the product and tech department currently makes up around 400 of them. This is a huge increase from where we were just five years ago.
Over the last five years, not only have we grown in size, but also in complexity. We have moved towards being a digital company. As a result, we now have many more front-end applications and web services, which we are using to construct ever more complex journeys and features. We have seen how quality roles have adapted, evolving from manual test analysts to test engineers; we’re now responsible for the creation and maintenance of robust test automation suites, but are also advocates for quality at all stages of development.
Throughout all this change, we test engineers found that we had neglected the fundamentals: who owns quality and how it should be delivered. We had to make a radical change in how products were tested at our company, and fundamental to that was a shift in attitude toward "who owns quality." But that didn't happen overnight. In this article, we'll describe how we got there.
The “before”: Testing was a disjointed discipline
Over time, testing at our company became a very disjointed discipline. We can’t pinpoint exactly when it began; it happened gradually "under the radar" over a long period of time.
To set the scene, within tech at our business, we’re split across domains that target the specific demographics that use our solutions. For example:
- Consumer: anything related to our website and mobile app for people who are looking for a new vehicle or just browsing
- Retailer: those who work on the tools we provide to individuals or to auto dealerships, our customers, who sell vehicles to consumers
- Platform: those who work on our core back-end services that power the rest of our tech stack
The product teams that serve these domains have diverged and become siloed in some ways, leading to wide variation in the technical skills, domain knowledge, and day-to-day responsibilities across the testers at our company. As an agile business, testers and developers often move between domains and teams as requirements change. The diversity of skills and knowledge can lead to problems in the transitions. Ideally, we want engineers of all skill sets to have a streamlined experience moving from team to team, thanks to a consistent application of strategy, processes, and some general domain knowledge with broad application.
Before we started implementing our new strategy, our test engineers were all over the charts in terms of technical ability. Some areas are inherently more technical, such as native apps. Test engineers for these apps require good technical skills to maintain and update our UI testing framework, which is a custom framework built from scratch using Appium and written in Kotlin. Other test engineers have worked in areas where only UI testing is required. As this is the only layer usually owned solely by the test engineer, this may mean they’ve not had need or opportunity to do much technical work.
Similarly, test engineers tended to have deep but not broad domain knowledge. They might move between different teams, but rarely did they move between domains. Having domain experts in an area with deep knowledge isn’t a bad thing, but it can lead to issues down the line when these individuals have little domain knowledge about other areas. Ideally, test engineers should be domain experts in their areas but also have enough knowledge of other domains to discuss and help where needed.
To apply a consistent approach to testing across the department, we would need to bring together these disjointed areas somewhat into a more aligned team. This would require testers to collaborate more frequently and intensely across domains and disciplines. Testers would also need to collaborate with developers and other members of the dev teams.
What did we do to address the issues?
We introduced a new testing strategy. Easy, right? Apparently not.
Having an agreed-upon testing strategy is something most tech firms aim to achieve. However, achieving this consistently across the development discipline can be very difficult. We are sure our company is not alone in having gone through this.
We found testing and quality were things our development teams 'just did' and developed over time, with iterations over time to achieve something that 'more or less' worked. The teams saw that doing anything drastically different would be hard work, so they had decided to leave it as it is. Sound familiar? We decided we had to change this by tackling the issue head on.
Creating and maintaining a testing strategy is an ongoing journey that takes a lot of time and effort, especially if you’re working with mature teams and heavily embedded processes. There have been bumps in the road, obstacles to overcome, and a light at the end of the tunnel, which often feels far away. Despite all this, improving quality is something we’re committed to achieving. Here’s our story, covering the highs and lows and what we have managed to achieve.
Building a pyramid of test types
In theory, our testing strategy was simple. We wanted to shift our testing left, which is the process of moving testing and quality earlier in the development lifecycle. We also wanted to follow a testing pyramid structure: a triangle-shaped strategy template that requires a greater number of low-level tests, like unit tests, and fewer high-level tests, like end-to-end tests. The idea is to catch bugs earlier, test faster, and reduce maintenance costs.
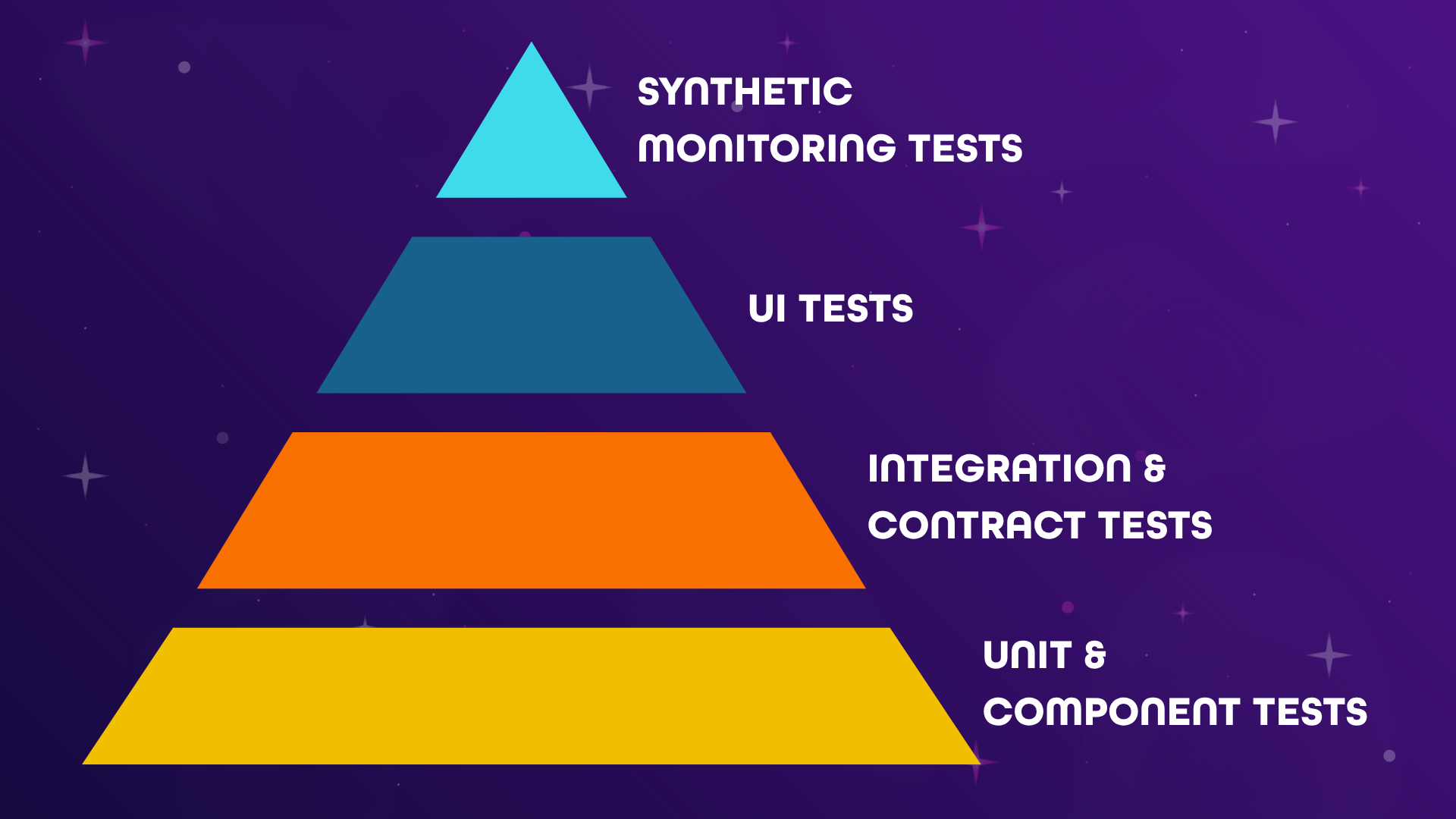
At the bottom of our pyramid are unit and component tests. These tests are quick to run, they focus on small isolated areas of code, and are an effective way to give us early feedback on issues. They can be used to cover things like:
- Error handling and validation
- Rendering of components on pages
- State changes
- Event handling, such as input changes
Next up, we have integration and contract tests. This section of the pyramid is smaller, and therefore, there should be fewer of these than unit tests. There’s a big difference with these tests in terms of how they’re actually used across our web and app platforms, but generally, they can be used to cover:
- Ensuring pages load correctly, returning HTTP 200 responses
- Ensuring server side components render as expected
At the middle of the pyramid are UI tests. These types of tests take much longer to run than tests lower in the pyramid. They run later in the release process and often can be flaky, causing pipelines to fail unnecessarily. We decided these tests should be limited in number, covering only:
- Happy path journeys
- Some important journeys which require additional assurance
At the top of the automated suite of tests are synthetic monitoring tests. These tests are designed to bring all aspects of the site together: platform, services, code. They run internally or externally, on a schedule, usually every 10 minutes. They may take the form of browser tests, loading our website and running a suite of end to end test cases. They may also take the form of API tests, verifying expected JSON payloads and HTTP status codes for given requests to RESTful services. They are used for business-critical cases which require live uptime monitoring and alerting.
Establishing goals and standards
To establish a strategy across testing requires more than just testers themselves getting on board with the idea. We also needed to get our tech leads, the heads of dev within our given workstreams, to agree and align principles across development in regards to testing. They need to be willing to collaborate with the test lead for their area and form a unified front, setting the expectations for the rest of the team.
A strategy that works only for one side is doomed to fail in the longer term. We believe a successful strategy in this space requires a longterm collaboration between dev and test, sharing ownership of the middle layers of the testing pyramid to ensure quality is considered at all layers and by all parties.
To reach this stage, we had to speak to our tech leads early in the process of defining our new strategy. The strategy needed to be built from the start in a way that would work for them as well. If we didn't involve them early, we’d risk a lot of wasted time and effort building a strategy that was unlikely to be adopted.
Doing the initial ideation together helped us to come to an agreement. We discussed ideas and principles leading to agreement on a common standard that could be applied across many areas. Our tech leads needed to agree to several aspects of this plan to make it work, such as:
- Including engineering time for both testers and developers on test-specific objectives
- Honoring quality principles throughout the software development lifecycle
- Considering testing at all stages of development, from the initial epic kick-off to the final release
- Treating testing as a first-class citizen within the application, providing a good developer and tester experience when working on testing within the application
- Committing to treating test failures seriously and prioritising work identified by failing test cases
There is never a one-size-fits-all solution. We’re an agile software house, and it’s important that our overarching strategies are themselves agile. A stringent strategy would lead to it being inapplicable to various teams, being ignored and defeating the point of a unified strategy. Each team had slightly different needs, so the strategy had to be agile and flexible as well as comprehensive. Some teams had differing levels of testing resource, different splits of front-end versus back-end devs who work purely on APIs and back-end systems. All of these teams needed a strategy that could work for them whilst acknowledging their different ways of working.
It’s a fine balance to build a strategy that is both agile enough to work for any team, whilst also being comprehensive and detailed enough to unify the efforts of disparate teams.
Meeting challenges of native apps
Our business has two fully native consumer apps: an Android app written primarily in Kotlin and an iOS app written primarily in Swift. These apps are well established, relying on older codebases that have been constantly maintained and updated over time. They are well utilised, with just under four million unique, active users every month. Our iOS app is our biggest consumer platform by a comfortable margin. We also have a custom back-end and front-end, server-driven UI system called Composable. You can find more information about Composable by checking out the links in our MoT profile.
Testing native mobile apps brings additional challenges that have to be considered by test engineers in that area. Release candidates must be prepared and submitted for review by both Apple and Google before they can be downloaded by end users. End users may choose not to update the app, and therefore, we need to make sure we don’t make any breaking changes in the back end that might break app versions older than the latest. In the longer term, dropping support for older versions of the app clients needs to be considered and planned. Composable helps us with some of these challenges, but they are still always present to some degree.
Evaluating new ideas and taking action
Another issue we have faced: where do we stop evaluating alternatives and come to an agreement on an approach? The tech industry is notoriously fast-paced, with new standards and technologies appearing all the time, giving us fresh ideas and perspectives on how testing can be done. Naturally, we are keen to explore these new ideas to see if they could enhance the way we work. As already mentioned, our journey of introducing the testing strategy has been a long one, and the end game is to standardise the way quality is done across all our teams. So what we absolutely want to avoid is a pivot in approach midway through implementation, as this would inevitably lead to rework.
We have battled with this at times. For example, a decision was made to change the tool we use for our end-to-end tests, going from Cypress to Playwright. There are a number of reasons we did this, which is a whole other story in itself. One of the main benefits was the ability to run tests in parallel, reducing our pipeline run times. As a business, this was deemed a big advantage to us. So naturally, after some discussion and investigation, we made the decision that Playwright would be our tool of choice.
We also changed the platform we use to run our tests. Previously, we used our platform agents to run our tests internally. Now we use an external platform capability hosted by Checkly. This is because our internal platform did not allow a consistent approach to testing. Our teams were using different build and run tools, and we did not have many, if any, linting rules and standards. The use of Checkly and our understanding of how we can best use its features have evolved over time, meaning our testing strategy has had to evolve and adapt in line with our new knowledge. For us, this change is one of the most beneficial to us.
As you can see, there are some big changes that we have decided are worthwhile accepting. There have also been things we have decided not to use or change. Change that makes sense, not change for change's sake, has been the key to our success. We make informed decisions and say no where appropriate. If you are looking to introduce any changes to your team, you need to be strict in your scope and be careful not to let it slip too much. Adaptation is a good thing, but too much will leave you and your teams in a pickle. You need to make sure you are smart with this if you are to succeed.
Building the framework according to the new strategy
Agreeing to do the work
Our development teams are busy. They work at nearly full capacity all the time, tending to new features, bug fixes, and other work items requested by the business. We knew we had a massive task at hand, so fitting in the adoption of a new testing strategy was another big hurdle. We had to go about getting our business stakeholders to understand the benefit of this piece of work and get them to prioritise it.
Historically, work like this has always been at the bottom of the pile. It would wind up in the black hole of those tickets in your backlog that never get picked up. We worked hard to sell the value to them. With time and effort, we got everyone on board, on paper at any rate.
Understanding the scope of work
Once we had the seal of approval, we had to take it to action, our next hurdle. We needed support from our developers to work through the backlog items to write new unit tests and check existing coverage. Not all test engineers can do that.
We had to approach this with two key areas of consideration: existing features and future features. One of the first issues we faced comes from our existing features and the fact our tech stack is very well established with lots of mature test suites already in place. Fixing these was going to be a huge job.
Part of our plan was to assess each of our active repositories to understand their testing coverage. We needed to know what types of tests we have, how many there were, if there were gaps, and if any of the tests often failed in the pipeline. With this information, we looked to refactor and restructure in line with our strategy. We realised early on that we had no easy way of doing this. We have too many pipelines running tests and to do this manually would take too much time.
We needed a baseline: some metrics we could bring together with all the information we needed. This is where our test metrics dashboard was born. The dashboard would give us a view of each of our pipelines’ overall coverage, their health and stability. And they would allow us to compare not only a pipeline's individual health over time but also how it was doing with respect to other pipelines. This in itself was a huge piece of work, requiring dedicated time and resources.
Refactoring the tests
Once the test metrics dashboard was running, we got closer to understanding our tests. Now we needed to look at actually refactoring all the apps. Our dashboard told us the following about one of our typical applications:
- We had over 2,000 tests running in a single deployment, made up of around 1,900 unit and component tests that run as part of the build.
- Over 160 end-to-end tests were running in the pre-production environment, using multiple tools including:
- Around 90 tests were running in production, acting as an extension of our pre-production end-to-end tests.
Seeing these numbers demonstrated to us the scale of the challenge we had decided to take on. It also told us that we had tests failing regularly. Pipelines were rerun multiple times due to flaky tests, and there was an overall run time of around 25 minutes.
We decided to tackle our Cypress tests first. We would find tests that could be shifted left and moved down to the unit layer or were duplicated by tests at that level. Then we would look at our remaining coverage and ensure the tests were covering only happy-path journeys. We got agreement from the technical leads that we could address this as part of our tech debt work.
Very slowly, one app at a time, we began addressing the problems. But we weren't done. Our end goal was a suite of tests in a pyramid structure. We had to consider Cypress tests, synthetic monitoring tests, visual regression tests, and unit tests. And this was for just one application.
The next hurdle was planned features. We needed to educate our teams to adopt and stick with the new strategy. This again took time as well as continued reinforcement.
The "after": Where we are now
We’re now about a year into our journey to change testing at our business for the better. We’ve made a lot of good progress, but we’ve still got a lot to do all the same.
Improved collaboration and shared ownership
Test engineers are collaborating much more closely with other functions of their respective teams. This applies on a micro level, where testers are always working with the tech lead to ensure coverage is applied sensibly and works for everyone. Teams are taking more shared ownership over the various layers of the testing pyramid, with shared ownership over central layers and knowledge sharing over the lower and top sections that have more exclusive ownership. Everyone is more aware of what test coverage is in place and better able to assess what else might be needed and better positioned to implement it.
A standardized test framework
On a macro level, we’re collaborating across product and operations to build a standardised, platform-integrated test framework that allows us to easily integrate UI and synthetic monitoring tests into our projects. So it's simple for anyone to create tests which run upon deployment of our applications or on a schedule, regardless of the technical stack of the specific application in test. This framework seamlessly integrates with our existing platform alerting and pipeline infrastructure, generating instant alerts for the right people at the right time if a synthetic monitoring test were to fail. We’re hoping that this solution will be the home of all tests in these layers in the long run.
Empowering individual team members
Throughout all of test engineering, we’re trying to open up more decisions and framework level changes so more people are able to self-serve. We want all of our test engineers to feel trusted and empowered to have discussions, make suggestions, and raise pull requests for changes or new features that may be required or useful to everyone as a whole. Everyone should be provided the scope to contribute, learn and grow to help shape the ecosystem and culture of testing at the business. We’re well on our way to helping empower each individual to do so.
Our test engineers and technical leads are continuously working together to ensure the quality standards are being met in our teams. They run education sessions, review pull requests, and collaborate with developers on coverage. Our bar is high and this ensures we keep it up there.
Despite being distributed amongst various domains and product teams, we’re all still one testing group.
For more information
- Hurdles of Testing Large-scale Software Systems, Michaela Greiler
- Experience Report: Introducing Change To An Organisation As A Test Consultant, Beren Van Daele
- Changing Testing Culture in a Ginormous Company, Jim Holmes

Android, iOS and web test engineer. Experience with Appium, Espresso, XCUITest, Playwright and Cypress. BSc Computer Science and MSc Computer Science by Research focused on human-computer interaction.

Highly experienced test engineer committed to driving a quality mindset into agile development teams ✌🏼
Comments




