Ujjwal Kumar Singh
SDET @ Skeps
He/Him
I am Open to Speak, Write, Podcasting, Teach, Work
Hi, I’m Ujjwal, a software tester and quality advocate. Exploring how quality works beyond tools and into systems, decisions, and trade-offs.
Substack: https://substack.com/@beinghumantester
Achievements





































Certificates

Awarded for:
Achieving 5 or more Community Star badges
Activity

thanked contributors on:
This is the first time we've had six people with cameras on on the TWiQ stage. Woop! Woop! 🎉Good humans being open and honest about things. Thank you, Judy, for leading the way. 🤩
earned:
It's good to celebrate a milestone
awarded TWiQ — This Week in Quality for:

It's good to celebrate a milestone
awarded Heleen Van Grootven for:

It's good to celebrate a milestone
awarded Judy Mosley for:

It's good to celebrate a milestone
Contributions
A moment of speaking for the first time at OSSA moment of hosting the first MOT MasterclassA moment of uploading my first YouTube videoA moment of speaking at my first online webinar with the Conti...
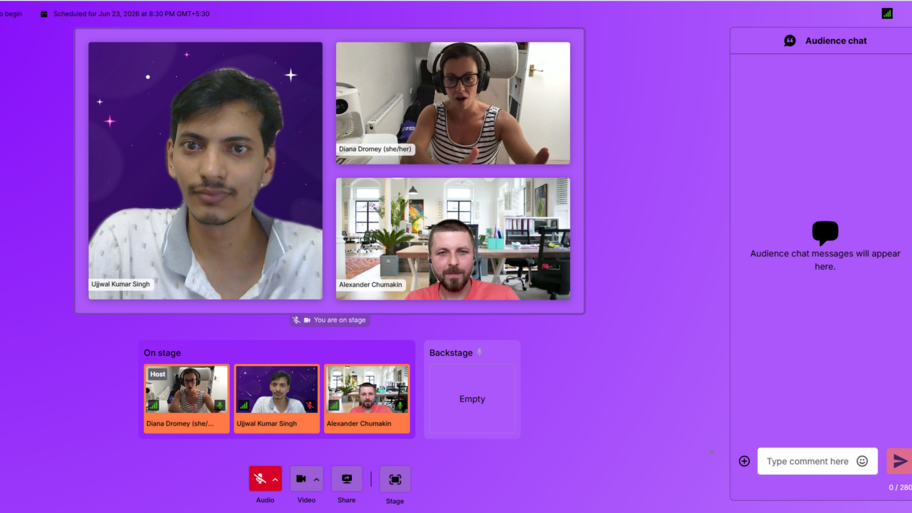
A few minutes before going live, checking notes, testing the mic, and hoping the internet would cooperate. 🙂



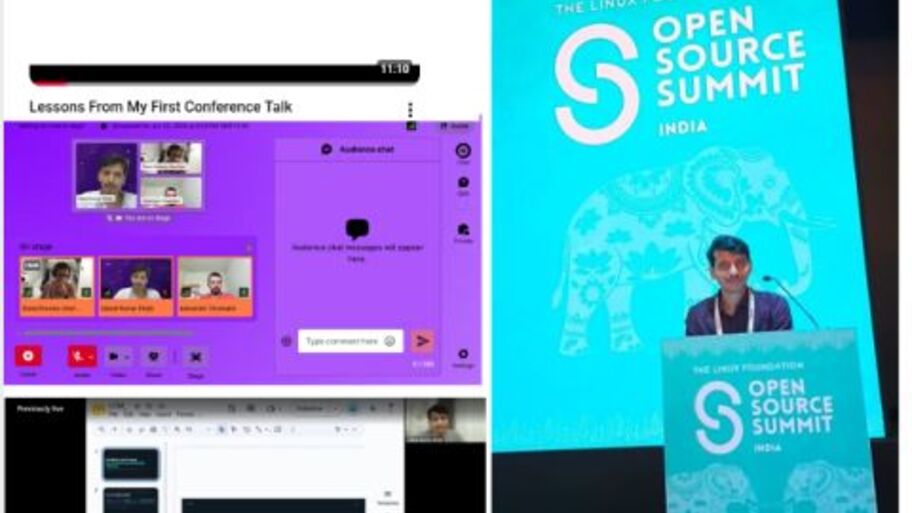
6 months ago, when 2026 started, I had a goal of speaking on a public platform, even though I speak at Taqelah, but it was a lightning talk and just 10 min talk. So today, as I delivered my first p...


The Open Source Summit, scheduled for 16–17 June, kicked off today, and this was the first thing I received as a speaker at the event.
Looking forward to the sessions, conversations, and connecting...

Inspired by the following challenge: Create a Moment: Ask MoTaverse Anything.I believe open source offers some of the best learning opportunities for testers. Whether it's understanding real-world ...




