
Emily O'Connor
Principal Quality Engineer
She/Her
Technical leader with a sixth sense for bugs. Avid learner, passionate about translating "dev-speak" to enable teams adopt automation and AI-accelerated quality engineering. I believe great software starts with user-focused problem solving, and automation should surface the bugs that PMs actually care about fixing.
Achievements













































Certificates

Awarded for:
Passing the exam with a score of 88%

Awarded for:
Passing the exam with a score of 95%
Activity

earned:
Call for Insights turns 45
earned:
2.3.0 of MoT Software Quality Engineering Certificate
earned:
Call for Insights turns 45
earned:
Call for Insights turns 45
earned:
5.2.0 of MoT Software Quality Engineering Certificate
Contributions

On the 15th of January 2026 myself and Ujjwal Kumar Singh joined a call and pressed record. We were curious to see what would happen. A few weeks later I’d done the same with Neil Taylor and Clare ...



A commit hook is a script that git executes automatically before or after a specific event in the version control lifecycle like committing, pushing or merging.You can have pre-commit hooks (prevention) and/or post-commit hooks (notifications or automation). A pre-commit hook is arguably more common, running after entering a git commit, with the cabability to abort the commit if certain quality standards aren't met such as linting rules, unit or smoke tests. If the hook outcome passes, git proceeds with the commit as normal, if not, git immediately aborts the commit, and the code stays in your staging area so you can fix it.

The OSCAR mnemonic is a tool that can be used to help understand the context around the problem, when coaching others to consider testing and quality.This model helps quality coaches guide their clients towards achieving their desired outcomes by focusing on their current situation, exploring their choices, taking action, and reflecting on their progress. By providing your testing expertise, you can guide them towards efficient strategies for achieving success.OSCAR stands for;
Outcome – help your stakeholder to define their ‘destination’, asking them open questions such as ‘what would success look like?’ or ‘what would you like to achieve in this release?’
Situation – help your stakeholder to define their current situation (the starting point).
Choices – generate as many alternative choices as possible and raise awareness around the consequences of each possible choice.
Actions – help the team member to clarify their next steps forwards and take responsibility for their own action plan, ‘what needs to be in place for this testing?’, ‘what will you do next?’ and ‘who could support this regression testing?’
Review – outline the conversation that has taken place up to now, create an ongoing process of review and evaluation so that if X needs testing in the future or Y goes wrong again, the team is equipped to perform hands-on testing or root cause analysis on their own. Ask open questions with curiosity to learn ‘are the actions moving you towards your outcome?’

XUnit is a family of testing frameworks like JUnit (for Java), NUnit (for .NET), and pytest (Python) that all follow a similar style and structure. They’re commonly used for unit testing. The X is just a placeholder, meaning each version is adapted for a specific programming language as mentioned.

San Francisco depot is a mnemonic for the SFDPO software exploratory testing heuristic. SFDPO stands for Structure, Function, Data, Platform and Operations. Each of these represents a different aspect of a software product.StructureStructure is what the product is. This is its physical files, utility programs, physical materials, etc.
FunctionFunction is what the product does. This is like the product's functional requirements. How does it handle errors? What is its UI? How does it interface with the operating system?
DataData is what the product processes. What kinds of input does it process? This can be input from the user, the file system, etc. What kind of output or reports does it generate? Does it come with default data? Is any of its input sensitive to timing or sequencing?
PlatformPlatform is what the product depends upon. What operating systems, browsers, runtime libraries, etc. does it run on? Does the user need to configure the environment? Does it depend on third-party components?
OperationsOperations are scenarios in which the product will be used. Who are the application's users? Where and how will they use it?

Dogfooding refers to software developers and companies using their own products and services, just like their customers do.Imagine a chef who will not taste their dish. It makes you think, doesn’t it? The same idea applies to businesses that do not use their products. Here is the answer to what is dogfooding. It shows how much a company believes in what creates. It helps the development team see and experience the product value directly.Dogfooding, or Eating your own dog food, helps you see what your customers see.

SCA (Software Composition Analysis) tools scan your manifest files (e.g. your package.json) against known vulnerability databases. They're looking for known vulnerabilities in third-party libraries, like malicious npm packages. SCA tools match every package and direct dependency in your project, regardless of whether your code actually uses the vulnerable functions which can create alert fatigue.Your teams may already have SCA tools in the pipeline, since it’s common to refer to them by the tool vendor such as Snyk, Endor Labs, Black Duck, OWASP dependency-check, Grype, GitHub Advanced Security and many others.

Any fool can write code that a computer can understand. Good programmers write code that humans can understand.
Clean code is code that is easy to read, easy to understand and easy to maintain. It is written for humans first and computers second.Here are some characteristics of clean code:
It expresses its intent clearly, meaning that variables, functions, and classes have descriptive names that tell you exactly what they do. Often following a naming and casing standard so that you cannot identify i ndividual authors.
Functions perform a single action.
Code adheres to the DRY principle (Don't Repeat Yourself). If you need to change a business rule, you should only have to change it in one place.
It isn't longer than it needs to be, including comments. It contains no dead code, unused variables, or speculative features (YAGNI - you ain't gonna need it).
It handles errors gracefully such as network failure, missing files or bad user input, and handles those exceptions explicitly, leaving the system in a predictable state.
It has minimal dependencies. Internally, code keeps connections between different parts of the software to a minimum and externally multiple packages aren't brought in for the same action (breaking DRY and increasing security surface area).
It is self-documenting. The code itself explains what it is doing and comments add why an approach was taken or the business logic being implemented, rather than explaining the lines of code they cover.
Similarly to self- documenting, clean code is verifiable. It is written in a way that makes it easy to test and it actually passes those automated tests consistently.
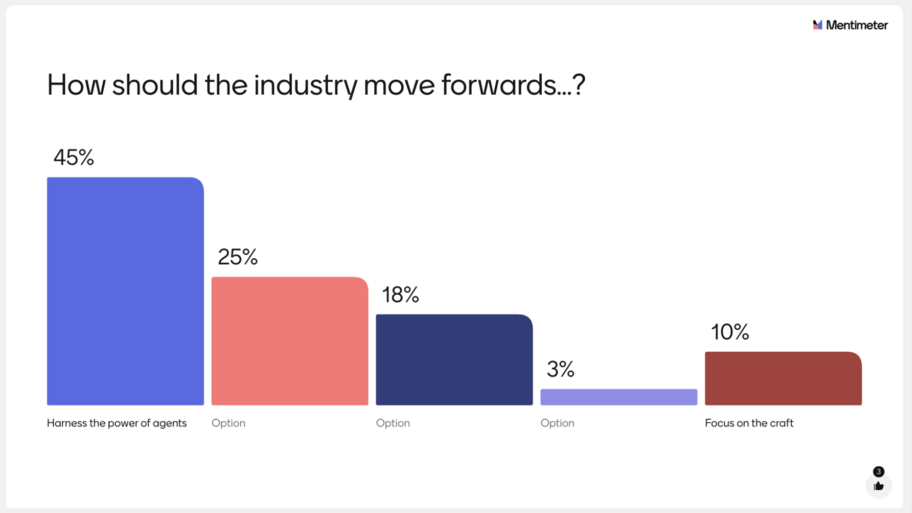
Yesterday, at Leeds Testing Atelier, I presented some slides around the use of AI (as a tool) to enable automation. After defining automation vs test automation and AI (technology that enables comp...

Emily kicks off track one
